- 该篇文章来自于 OSDI2020 From WiscKey to Bourbon: A Learned Index for Log-Structured Merge Trees
- 很久没看 LSM tree 的文章了,恰好这几天 OSDI2020 开了,果不其然还是有 LSM-tree 相关的,而且是和学习索引结合的,之前对 Learned Index 也是一知半解,所以拜读了一下。
- 这篇文章从写作和行文的角度讲写的特别的清楚,实验做的可能是我见过的最充分的,从一开始发现问题就开始用了大量实验来证明,后续的负载测试也极其丰富,回答了读者可能会有的各种各样的问题。值得一读。
Abstract
- Bourbon,一个利用了机器学习来提供快速查询的 LSM-tree
- Bourbon 使用贪婪的分段线性回归来学习 key 分布,以最小的计算代价实现快速查找,并根据成本和收益来决定何时学习是值得的。实验表明,查询性能相比于最先进的 LSMs 提升了 1.23x-1.78x
Introduction
学习索引是个啥?
- 作者上来先简要介绍了一波机器学习,当然是为了引出重点 学习索引,简单地讲,学习索引就是指当你查询一个 key 的时候,系统使用该索引(或者该函数)预测出你要查询的 key 所对应的位置,相比于传统的数据结构中的查找性能有比较大的提升,某些场景下可能提升可能更为明显,同时一定程度上因为不直接构建具体的数据结构节省了空间开销。基于这项工作,很多人提出了更好的模型、更好的树结构来减少对基于树的索引结构的访问和开销。
学习索引和 LSMs 能擦出啥火花?
两者理论上的矛盾
- 现有的学习索引大多是基于数据库场景中的 B 树来做的,很少有人提出说将学习索引应用到 LSM-tree 上,所以作者就尝试着把学习索引的想法应用到 LSM-tree 上(LSM-tree 的应用就不再具体介绍)。那么问题来了,为什么其他人没想到说把学习索引用到 LSM-Tree 上呢?主要是因为学习索引主要针对只读设置而量身定做的,而 LSMs 则主要是针对写进行了优化。
- 听着很抽象?那先简单解释一下。LSM tree 是对写比较友好的,但是写操作会影响学习索引,因为学习索引通常是基于原有的数据学习出来的,现在数据都变了,那你索引肯定得需要做出相应的改变才能保证你索引的准确性,最直接的办法当然是直接再学习。
- 然而,作者发现 LSMs 非常适合用于学习索引,虽然写操作修改了 LSM,但树的大多数部分是不可变的;因此,学习一个预测键/值位置的函数只需要完成一次,并且只要不可变数据存在就可以使用它。然而也有别的问题,可变的键或值大小使学习预测位置的函数变得更加困难,过早地执行模型构建可能导致大量的资源浪费。
Bourbon 做了啥
- 作者研究了 WiscKey,得出了几条 guidelines
- 虽然学习 LSM 中稳定的低级别是有用的,但是学习更高级别也会带来好处,因为查找必须始终先搜索更高级别
- 并不是所有的文件都是相同的:一些文件即使在较低的级别也是非常短暂的:系统必须避免学习这些文件,否则会浪费资源
- 工作负载和数据感知非常重要:根据工作负载和数据加载方式,了解树的某些部分可能比了解其他部分更有益
- Bourbon 基于 WiscKey 实现,WiscKey 原本大约 20K 行代码,Bourbon 增加了大约 5K 行,使用分段线性回归,这是一种简单但有效的模型,能够在很小的空间开销下实现快速训练(即学习)和推理(即查找),使用文件学习:模型建立在文件之上,假设一个LSM文件一旦创建,就不会被修改。实现了一个成本效益分析器,它动态地决定是否学习一个文件,在最大化收益的同时减少了不必要的学习。
Background
LSM & LevelDB
- 如下图所示是 LevelDB 和 WiscKey 的原理示意图。具体的介绍请参考其他资料,此处不再详细展开。本文中提到的 higher level 是指存放了更新的数据的 level,lower level 是指存放了更老的数据的 level。
- 简要介绍查询步骤,如图所示,便于后文引入学习索引:
- step1. FindFiles:如果 key 在内存中的 tables 中没有找到,LevelDB 将会查找到一组候选的来自磁盘的可能包含键 k 的 sstables。最坏的情况是 k 可能出现在所有 L0 文件中(因为重叠的范围),并在每个连续级别的一个文件中
- step2. LoadIB+FB:对于每一个候选的 SSTable,其索引块和布隆过滤器块首先被加载
- step3. SearchIB:对索引块进行二分查找,从而找到可能包含 k 的数据块
- step4. SearchFB:查询过滤器判断 k 是否存在对应的 datablock 中
- step5. ReadValue:如果 k 在对应的 datablock 中,相应地读取出对应的 value,然后查询结束。如果上一步的 filter 显示该 key 不存在或者对 datablock 查询时没有找到相应的 key,搜索操作将继续在下一个候选文件中执行
- NOTICE:blocks 不一定总是从磁盘中加载出来的,index block 和 filter block,以及经常访问的 data blocks 很有可能就在内存中可以被直接访问(文件系统缓存)。
- 作者对于索引的步骤和数据访问的步骤做了简单区分。 本文目标即为减少索引过程中的开销。
- FindFiles, SearchIB, SearchFB, and SearchDB 都是通过文件和 blocks 找到对应的键,也就是所谓的 indexing steps
- LoadIB+FB, LoadDB, and ReadValue 从存储中读取数据就是所谓的 data-access steps
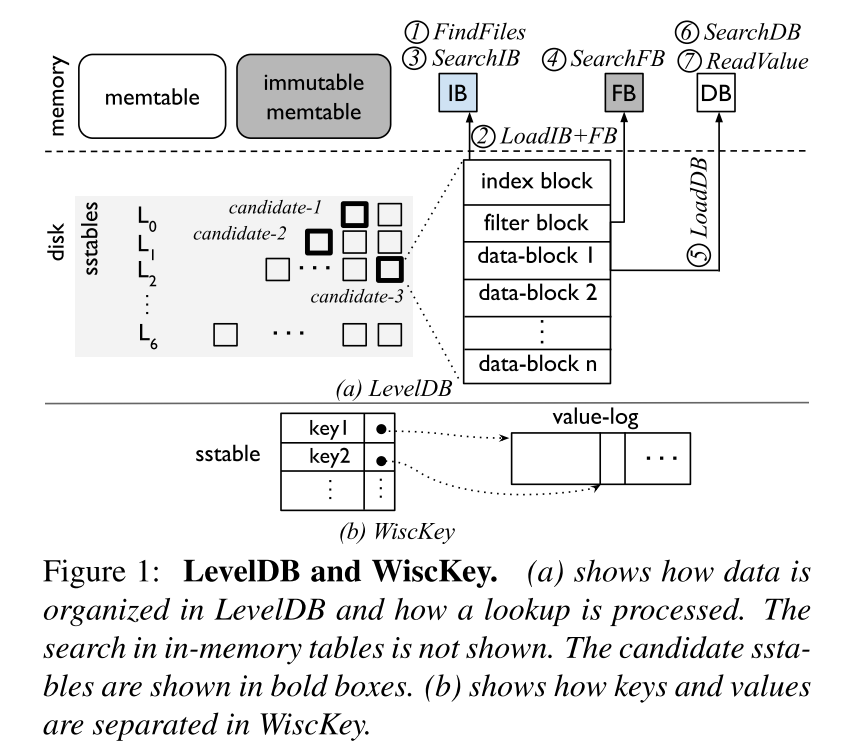
WiscKey
- WiscKey 是为了解决 LSM-Tree 中比较严峻的写放大问题而提出的,架构如上图所示,主要是讲 Key Value 分离,只是对 Key 使用 LSM 存储,Value 直接使用 Value Log 进行存储,因为数据量小了,写放大也就得到了缓解,同时因为比较小就可以缓存在内存中,因此一个查询操作可能最终只涉及到一次 IO 操作来读取 Value Log 上指定位置的 Value
Optimizing Lookups in LSMs
- 因为 LSM Tree 本身结构的原因,对于 LSM Tree 的查询可能需要对多个 level 进行查询,而且 LSM Tree 本能就是以写性能见长的,在读性能方面表现较差,所以对 LSM Tree 的读操作进行优化就很有必要。
- 受学习索引的启发,现在有很多工作考虑使用机器学习模型来替代传统的索引结构,核心思想是针对输入训练一个模型(使用如线性回归或者神经网络的方法)从而预测出输入对应的记录子啊排序好了的数据集中的具体地址。模型可能有误差,因此预测有一个相关的误差界。在查找过程中,如果模型预测的键的位置是正确的,则返回记录;如果错误,则在错误范围内执行本地搜索。例如,如果预测的位置是 pos,而最小和最大的误差范围是 和 ,那么根据错误的预测,在 pos - 和 pos + 之间进行局部搜索。
- 学习的索引可以大大加快查找速度。直观地说,一个学习过的索引将 b 树的 O(log-n) 查找变成 O(1) 操作。根据实际的经验表明,学习索引提升 B 树的查询性能约 1.5x-3x
- 传统的学习索引不支持更新,因为在现有数据上学习的模型会随着修改而改变。但是,LSMs 在写密集型工作负载中的高性能很有吸引力,因为它们只按顺序执行写操作。因此提出了关键问题给:如何实现学习索引同时保证 LSM 对写性能带来的提升?
Learned Indexes: a Good Match for LSMs?
Learned Indexes: Beneficial Regimes
- LSM-Trees 中的查询操作包含索引和数据访问两个方面的操作,如前面章节所述。优化后的索引如学习索引可以减少索引的一些步骤的开销,但是对于数据访问的开销没什么影响。在 WiscKey 中,学习索引可以减少如 FindFiles, SearchIB, and SearchDB 的开销。因此如果索引在总查找延迟中占相当大的比例,学习索引就可以显著提升查询的性能。
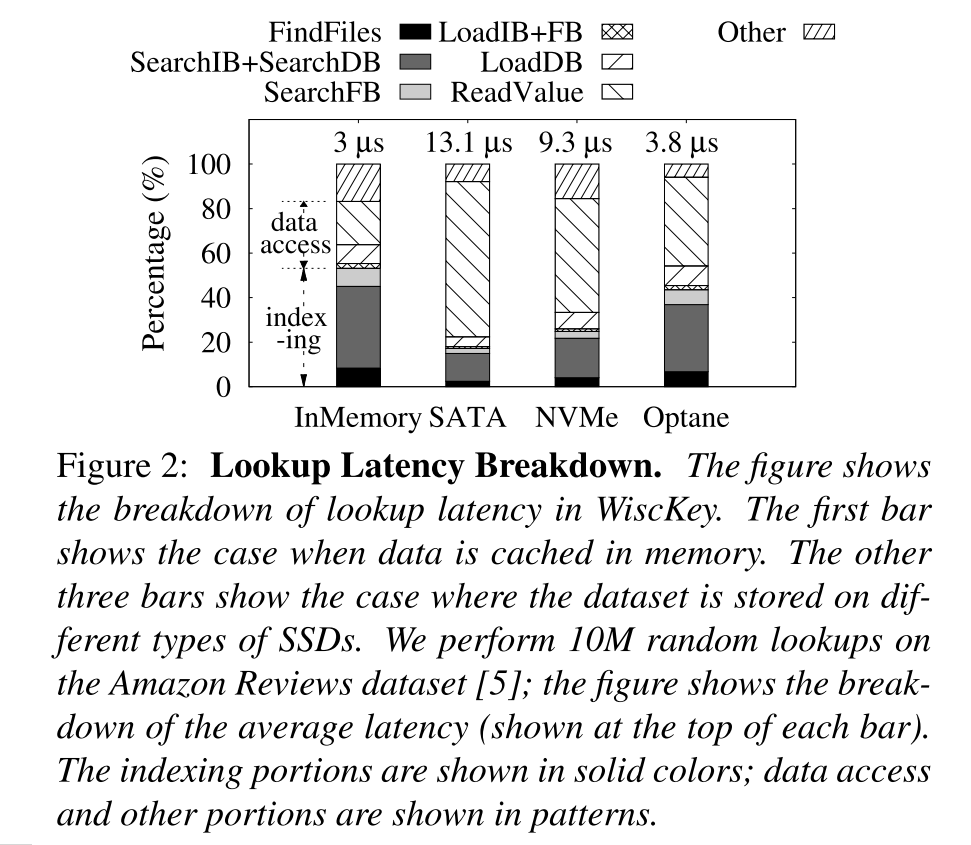
- 首先,当数据集或它的一部分缓存在内存中时,数据访问成本很低,因此索引成本就变得很重要。下图展示了在 WiscKey 中的延迟分解情况。柱状图的第一条显示了全部缓存在内存中的情况,第二条显示了数据存储在 SATA SSD 上的情况。其实第一条就相当于有缓存的情况,数据访问和索引成本对延迟的贡献几乎是相等的,优化索引部分可以将查找延迟降低约 2 倍,当不缓存数据集时,数据访问成本占主导地位,因此优化索引可能产生较小的好处,大约只有 20%。
- 然而,学习索引并不局限于数据缓存在内存中的场景。它们为当前流行的快速存储设备提供了优势,并且可以在正在出现的更快的设备上发挥更大的作用,如图所示随着设备的升级,即便延迟大大降低,但是索引结构的操作所占的延迟比重越来越大,如在 Optane SSD 中,索引结构的操作占据了大约 44% 的比例,因此优化索引结构的相关操作可以将性能提升约 1.8x。随着存储器件的发展,学习索引能够发挥的效果也越来越显著。
Learned Indexes with Writes
- 与传统索引相比,学习索引为只读分析工作负载提供了更高的查找性能。:然而,学习索引的一个主要缺点是它们不支持诸如插入和更新之类的修改,因为修改操作改变了数据的分布,所以模型就必须重新学习,对于写密集型的负载就常常需要重建模型,频繁的重建就会导致比较高的开销。
- 乍一看,学习索引似乎并不适合那些 LSMs 优化的写密集的负载,然而,我们观察到 LSMs 的设计很适合学习索引。我们的关键认识是,尽管更新可以改变 LSM 树的一部分,但大部分仍然是不变的。具体来说,新修改的项缓冲在内存结构中,或者存在于树的较高级别中,而稳定的数据驻留在较低级别。考虑到数据集的很大一部分位于稳定的、较低的级别,对这一部分的查找可以更快,而无需或只需进行少量的重新学习。相比之下,在更高层次的学习可能没有那么有效果,它们变化的速度更快,因此必须经常重新学习。
- 我们还认识到,SStable 文件的不可变特性使它们成为理想的学习单元。一旦学习之后,这些文件就再也不会被更新,因此一个模型可以一直被使用,除非该文件被替换。除此以外,SSTable 内的数据还是有序的,有序的数据就可以采用更简单的模型学习,一个级别是许多不可变文件的集合,也可以使用简单的模型作为一个整体来学习。一个级别中的数据也进行了排序:对各个sstable进行了排序,并且在sstable之间不存在重叠的键范围。
- 进行了一些实验来证明上述结论,实验的目标是确定一个模型在多长时间内是有用的,以及模型使用的频率。只要SSTable 文件存在,为该文件建立的模型就有用,因此,我们首先测量和分析 SSTable 的寿命。一个模型被使用的额频率将由内部查询的次数决定,因此只需要测试每个文件的内部查询次数即可,因为模型也可以基于整个 level 构建,所以作者也测试了 level 的 lifetimes,实验是基于 WiscKey 做的,但作者认为对应的实验结论也应该适用于大多数 LSM 的实现。
SSTable Lifetimes
- 下图 a 显示了不同层级的 SSTables 文件的平均寿命(寿命通过使用文件的创建时间和删除时间来衡量)。
- 较低级别的 SSTable 文件的平均寿命大于较高级别的。
- 在较低的写比例的负载下,即使是较高级别的文件也有相当长的生存期,但较低级别的寿命此时更长
- 即便随着更高的写比例导致文件的寿命下降,但是对于低级别的文件而言,寿命还是很长
- 图 b 展示了 5% 的写比例的情况下 L1 和 L4 的寿命的分布情况, 可以发现有的文件寿命非常短,有的文件寿命非常长。如 L1 的大约 50% 的寿命只有 2.5s,如果过了该临界值,寿命就会变得特别长,超过五分钟。而对于 L4,只有很少的文件寿命很短,大约有 2% 的寿命不超过 1s,造成该现象的原因可能是:
- 压缩一个 Li 层的文件会在 Li+1 中创建一个新文件,该文件会被立即选择用于压缩到下一个级别
- 压缩一个 Li 层的文件会在 Li+1 中创建一个新文件,该文件与从 Li 压缩的下一个文件有重叠的键范围
- 图 c 展示了不同写请求比例下 L1 和 L4 的寿命分布,规律和 5% 时大体相同。
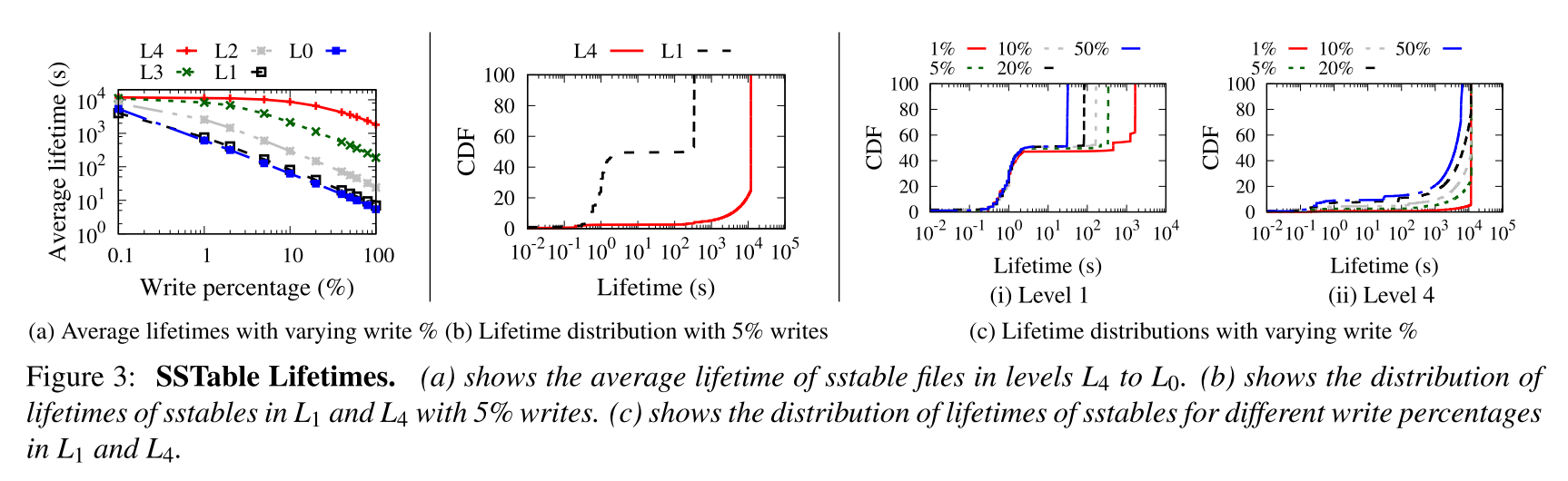
- 于是乎总结出了两条 guidelines:
- Favor learning files at lower levels:学习索引最好用于较低层次的文件,因为这些文件的寿命通常比较长
- Wait before learning a file:学习索引最好在某个文件存活的时间达到一定阈值之后才开始学习,因为有的文件寿命可能很短,即便是在一些较低层次的文件,因为存活持续了一段时间之后该文件才可能存活的比较长时间。
Number of Internal Lookups Per File
- 为了测试模型的使用频率,就分析了 SSTables 对应的内部查询次数。如下图所示,图 a 显示了数据集以一个随机顺序加载的情况,较高层次对应的总的内部查询次数更多,即便是很大一部分数据驻留在较低的级别上(图 (a)(ii) 则显示了查询不命中的情况),而如图(a)(iii)所示的查询命中的情况时候,低级别的文件的查询次数更多。结果表明更高级别的文件通常服务于一些不命中也就是 negative 的查询操作,虽然采用了 BloomFilter 来尽可能加速 negative lookup 的过程,但是 index block 在查询 filter block 之前还是会被查询。
- 同时还针对 zipfian 的负载(大多数请求都是针对一小组键的)下进行了同样的测试,结果表明大多数情况下都和随机加载的负载是相似的,除了 positive lookup,如图 (a)(iv),在 zipfian 负载下,更高层级的文件处理更多的 positive lookups,因为负载经常访问一小组常被更新的键,因此这组键被常常存储在更高的 level 上。
- 图 b 显示了数据集被顺序加载(keys 按照升序或者降序的方式被插入)的情况,相比于随机加载的情况,就没有了 negative lookups,因为不同 SSTable 的键不会重叠,即便是在不同的 level 上也不会重叠,FindFiles 步骤可以直接找到可能包含该 key 的唯一的文件。因此,较低的级别提供更多的查找,并可以从学习索引中获得更多好处。
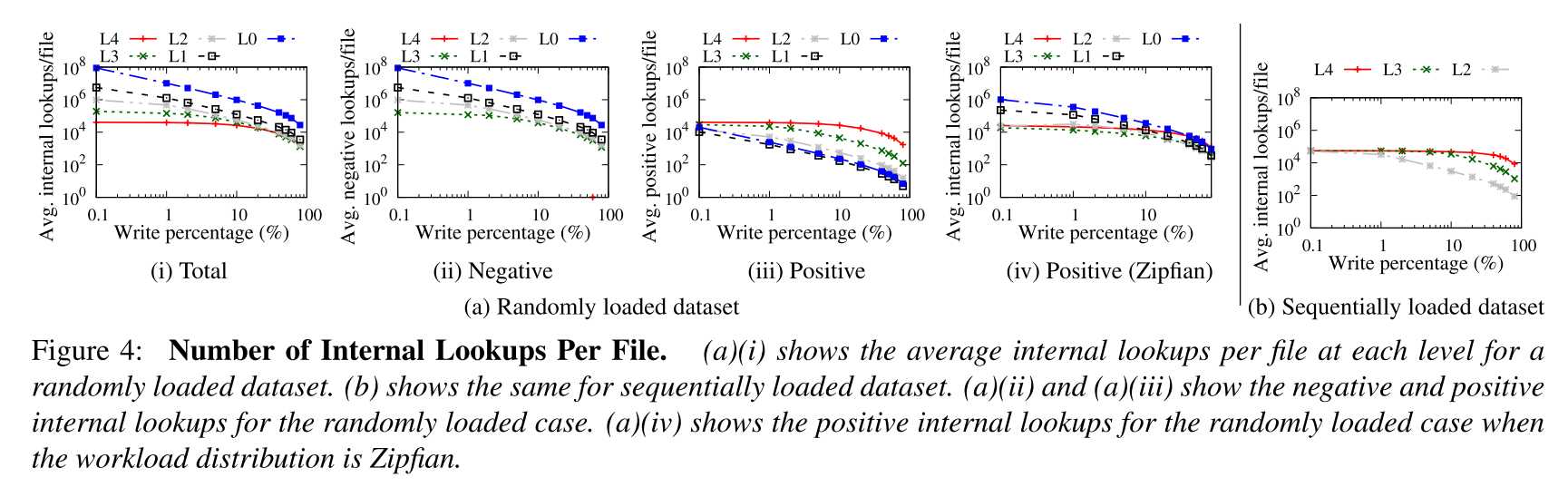
- 从上述的实验观察中也得到了两个 guidelines:
- Do not neglect files at higher levels:即便更底层次的文件寿命更长,处理的查询也更多,但是更高层次的文件在某些负载下也是可能处理很多 negative 甚至 positive 的查询请求的,因此学习索引在高层次的文件中也能让内部查询更快
- Be workload- and data-aware:尽管大多数数据位于较低的级别,但如果工作负载不查找这些数据,那么学习这些级别带来的收益就很悠闲;因此,学习索引必须能够感知工作负载的情况。除此以外,数据被加载的顺序性也会影响那些层处理更多的内部查询请求,即会影响请求处理的层级分布情况,因此学习索引还需要感知数据的情况。内部查询请求次数可以同时代表工作负载和数据加载顺序,所以基于请求次数就可以动态地决定是否要学习某个文件。
Lifetime of Levels
- 前面章节有描述过一整个层级也是可以被学习的,所以作者测试分析了整个层级的寿命。
- 因为 L0 层无序,L0 层的文件可能有重叠的键范围,所以不能应用层级学习的策略。一旦一个层级被学习了之后,任何对于该层级的更新都可能导致重学习,而层级更新则是指新的 SSTable 文件在该层次被创建,或者一个已经存在的被删除,因此,一个层级的的寿命与单个 SSTable 相同或更短。在层级的粒度上进行学习的好处是不需要在单独的步骤中找到候选 SSTables,而是在查询时候模型直接输出对应的 SSTable 和文件内的偏移。
- 下图 a 展示了在 5% 的写比例下不同层级的文件变化情况,纵轴上的 0 表示当前时间该层级没有发生变化,此时则可以进行学习。如果大于 0 则表示该层级发生了变化,因此就需要进行重新学习。更高层次对应的文件变化频率更高。随着级别的下降,更改的文件的比例会减少,因为较低的级别在许多文件中包含大量数据
- 对层级文件的更改通常是突发性的。该突发通常是由压缩引起的该层级中的很多文件同时被修改,因此这些突发的时机在不同层次表现的时间基本相同。这背后的原因是,对于我们使用的数据集,级别 L0 到 L3 已经满了,因此任何在一层上的压缩都会导致级联压缩,最终在未满的 L4 级别上存放。在这些突发情况之间层级的文件基本会保持平稳不会发生变化。
- 但是随着写请求比例的上升,突发间隔会逐渐减小,如图 b 所示,层级的平稳周期将大幅减小。如图所示 5% 时,大约有 5 分钟的周期,在 50% 的时候,就只有大约 25s 了。

- 基于上述实验,又总结了一条 guidelines
- Do not learn levels for write-heavy workloads:当写请求比例较低的时候,学习一整个层级还算比较合适,但是写密集型的负载,因为层级寿命变得很短就可能导致很频繁的重新学习。
Summary
- 通过对 WiscKey 的实验分析,总结了五条 guidelines:
- Favor learning files at lower levels
- Wait before learning a file
- Do not neglect files at higher levels
- Be workload- and data-aware
- Do not learn levels for write-heavy workloads
Bourbon Design
Learning the Data
- 回顾学习索引的目标:预测 key 在一个有序的数据集中的位置。
- 本文设计了两种学习索引,对应学习的粒度不同。
- File Learning:预测 key 对应的在文件内的偏移
- Level Learning:预测出对应的 SSTable 文件和文件内的偏移
- 对于学习索引的要求:无论是学习过程还是查询过程,开销都需要很低才能真正优化整个系统。除此以外,因为优化的是磁盘上的数据结构对应的存储系统,空间的开销也需要尽可能的小。作者发现分段线性回归(PLR)能够同时满足上面的要求。PLR 的本质是用一些线段来表示有序的数据集,PLR 构造了一个有误差限制的模型,每个数据点 d 必须在范围 [ − δ, + δ] 内,其中 数据集中的 d 预测的位置,δ 是提前定义好的误差限制。
- 为了训练 PLR 模型,Bourbon 方案使用了 Greedy-PLR 算法,一次处理一个数据点,如果数据点不能在不超出定义的误差限制的情况下被添加到当前的线段中,那么将创建一个新的线段,并将数据点添加到其中,最终 Greedy-PLR 生成了一组代表数据的线段。Greedy-PLR 的运行时间与数据点的数量呈线性关系。
- 一旦模型学习完成,推理就会很快。首先,找到包含键的正确线段(使用二分查找)。在该线段内,目标键的位置是通过将键与直线的斜率相乘并加上截距得到的。如果键不在预测的位置,在误差范围内进行局部查询。因此查询操作除了常数时间做局部搜索,只需要花费 的时间,其中 s 是线段的数量。PLR 的空间开销很小:每个线段只有几十个字节。
- 其他模型诸如 RMI,PGMIndex,splines 等可能更适合 LSMs 且提供比 PLR 更好的表现,未来可以采用这些模型来进行实现。
Supporting Variable-size Values
- 如果 KV 对大小相同的话,学习索引预测 KV 对的偏移量将会很容易,模型可以将 key 的预测位置乘以 KV 对的大小,从而产生最终的偏移量。但是对于许多系统而言,往往允许任意大小的 KV 对。
- Bourbon 要求 Key 是固定大小的,但是 Value 可以是不固定的。作者认为这是一个合理的设计,因为大多数数据集有确定大小的 key,比如 user-id 通常有 16bytes,但是 value 的大小就不固定了。即使 keys 大小不同,可以填充使所有 keys 的大小相同。Bourbon 通过借鉴WiscKey的键值分离思想来支持可变长度的 value。
- Key Value 分离的方式,Bourbon 中的 SSTables 就只会包含 key 和对应的指向 value 的指针,value 被单独维护在 value log 中,在这样的模式下,Bourbon 通过从模型中得到预测的位置,然后乘以对应的记录大小(通常是 keySize + pointerSize),从而获取要访问的 KV 对的偏移量,Value 指针用作 Value Log 的偏移量,最终从该日志读取值。
Level vs. File Learning
- 前面的分析表明文件的寿命比层级的寿命通常更长,特别是在写密集的负载下,也就意味着以文件的粒度进行学习可能是更好的选择。作者为了在 file 和 level 之间进行权衡测试了不同负载下对应的性能,初始化的时候都加载一个数据集并构建模型,对于只读负载,模型不需要重新学习,在混合负载中,因为数据的改变模型需要重新学习。
- 如下表所示,混合负载下,Level 明显不如 File,因为有稳定的写入流,系统无法对 Level 进行学习。只有 1.5% 的内部查找采用模型路径;这些查找是在加载数据之后以及初始的 Level 模型可用时执行的。作者观察到所有尝试的 66 次 level 学习都失败了因为在学习完成之前 level 已经发生了改变。由于重新学习的额外成本,level 学习的性能甚至比 50% 写操作的基线还要差.而使用 file model,大比例的查询操作都能从学习索引中获益,因此 file model 相比于基线性能有所提升。
- 对于读敏感的负载( 5% 的写),尽管 level model 相比于基线有一定的提升,但还是比 file model 性能表现要差,原因还是因为重新学习的额外成本和仅作用了有限的查询操作,带来的提升有限。
- 只有在只读负载下,Level 学习才能带来比较大的提升,甚至比起 file learning 都提升了 10%,因此,只有只读工作负载的部署可以从层级学习中获益。
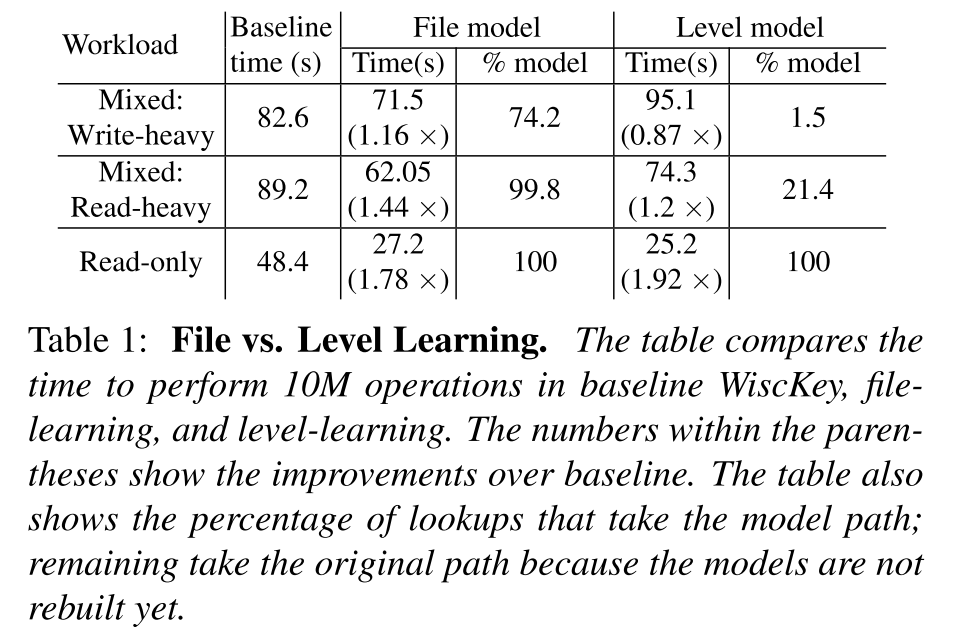
- 鉴于 Bourbon 的目标是在支持写操作的同时提供更快的查找,对于学习粒度来说,level 并不是一个合适的选择,所以 Bourbon 默认使用文件学习,但同时也会支持 level 学习以便适应只读负载。
Cost vs. Benefit Analyzer
- 因为还是有部分文件的寿命较短,对这类文件的学习可能是对资源的浪费,所以需要开销和收益的分析机制来决定是否要对某一个文件进行学习。
Wait Before Learning
- 从前文的 Guidelines 中了解到,需要设定一个等待时间的阈值 ,即在学习一个文件之前,需要等待相应的时间,该系数的具体值体现了开销和收益的权衡。值太小,导致一些寿命较短的文件也被学习,引入了较大的开销,值太大导致执行大量的查询的时候,因为模型还未学习构建,导致大量的查询不能通过学习索引来进行优化,导致性能下降。
- BOURBON 将 设置为学习一个文件大概所需要的时间。测试发现学习一个文件(最大 4MB)的最长时间大约为 40ms,作者保守地将 设置为 50ms
To Learn a File or Not
- 虽然现在有了 ,但是一个文件即便是存活了很长时间但是可能也不是特别有益的。作者实验发现更低级别的文件通常寿命更长,对于有的工作负载和数据集,他们服务的查询操作比更高级别的文件要少得多,更高级别的文件尽管寿命较短,但是在有的场景下服务了大量的 negative lookups。因此除了考虑模型对应的开销以外,还需要考虑模型可能带来的收益。如果一个模型的收益()大于构建该模型的开销()那么该模型就是有利的。
Estimating
- 评估开销的一种方式是假设学习过程完全是在后台完成的且不会影响系统其他部分,那么开销就为 0,如果有很多空闲的 core,学习线程可以利用它们,这样就不会干扰前台任务(工作负载的处理或者压缩过程等)。但是 Bourbon 采用了一种比较保守的办法并且假设学习线程会干扰和减慢系统的其他部分,所以,Bourbon 假设开销等于为单个文件构建 PLR 模型的时间 ,我们发现,这个时间与文件中的数据点数量成线性比例,因此可以通过将训练一个数据点的平均时间和该文件中包含的点的数量相乘从而得到该时间。
Estimating
- 评估模型带来的收益相对比较复杂,直观地说,模型为内部查找提供的好处由 给出,其中 和 分别是基线和模型路径中查找的平均时间。如果一个文件在生命周期中服务了 N 个查询请求,那么该模型的净收益即为 。作者将查询操作又划分成了 negative 和 positive,因为大多数 negative 的查询操作在 filter 处就终止了,所以最终的收益模型为:。其中 和 则是 negative lookup 和 positive lookup 的数量,T 为对应分类下的时间。
- 如果不知道文件将执行的查找次数或查找将花费的时间,则无法计算文件的 。因此分析器为了预估这些指标,维护了这些文件在他们生命周期内的统计信息,为了估计文件 F 的这些指标,分析器使用与 F 处于同一级别的其他文件的统计数据,我们只在同一层次上考虑统计数据,因为这些统计数据在不同层次上差异很大。
- Bourbon 在学习一个文件之前的等待时间里,查询操作可能在 baseline 的路劲中被服务处理,Bourbon 将把该过程的处理时间作为基线的查询处理时间 , , 和 将使用同一层级的其他文件的平均模型查询时间来进行估计。对于 和 ,分析器首先获取该级别中其他文件的平均 negative 查找和 positive 查找,然后,将其按 的倍数进行缩放,其中 s 是文件的大小, 是该层级的文件的平均大小。在估计上述数量的时候,Bourbon 将会过滤掉寿命较短的文件。
- 当模型开始引导时,分析器可能还没有足够的统计信息,所以,初始化的时候,Bourbon 以 always-learn 的模式来运行,一旦足够的统计信息收集到了之后,分析器就可以开始执行开销和收益的权衡,来判断 和 的大小关系来决定是否学习某一个文件。如果同时选中了多个文件进行学习,Bourbon 则把多个文件放在一个最大优先级队列中,按照 的顺序进行排序,因此优先级最高的文件对应的收益也就最大。
Bourbon: Putting it All Together
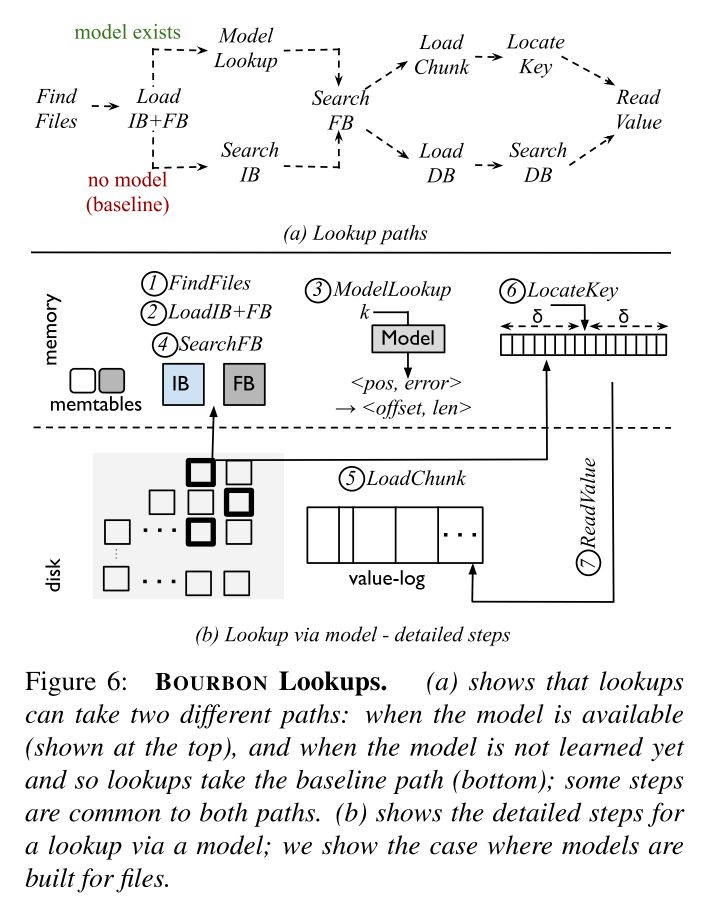
- 总体的流程如下图所示,主要分为两条路径:model exist 和 no model 对应的 baseline。baseline 和前文描述的 LevelDB 的检索方式基本相同,只是此处采用了 WiscKey 的方式来布局。
- 对于学习索引的查询方式,步骤如下:
- step1. FindFiles:因为使用了文件学习,所以该步骤需要执行,即找到候选的 SSTables 文件
- step2. LoadIB+FB:BOURBON 加载了 filter 和 index block,这些块可能已经被缓存在内存中了
- step3. Model Lookup:FB: BOURBON 在候选的 SSTables 文件中对要查询的 Key 进行检索,模型相应地输出键 k 对应的文件内偏移 pos 和误差边界 δ。然后 BOURBON 计算包含记录 pos−δ 到 pos+δ 的数据块
- step4. SearchFB:首先检查该数据块对应的 filter block 来判断 k 是否存在,如果存在,则 BOURBON 计算要加载的块对应的字节范围(因为 keys 和 pointers 大小固定,计算相对简单)
- step5. LoadChunk:加载对应的字节范围
- step6. LocateKey:键位于加载的块中,那么该 key 将位于预测的位置上(加载的 chunk 的中点);如果不在,BOURBON 将会对该 chunk 执行二分查找
- step7. ReadValue:使用相应的 Value Pointer 从 ValueLog 中读取对应的 Value
Possible improvements
- BOURBON 少了一些 features,现有的实现中,不支持字符串 keys 以及 keys 的压缩
- 对于字符串键,我们计划探索的一种方法是将字符串视为base-64整数,并将它们转换为64位整数,然后可以采用本文描述的相同学习方法。虽然这种方法可以很好地用于小 keys,但是大 keys 可能需要更大的整数(大于64位),因此高效的大整数数学可能是必不可少的。
- BOURBON 暂时不支持 level 和 file model 的切换,目前只是一个静态配置。
Evaluation
- 测试之前抛出了几个关键问题:
- BOURBON 究竟优化了查询的哪些部分?
- BOURBON 在有模型但没有写的情况下表现如何?性能会随着数据集、加载顺序以及请求分布的变化发生什么样的变化?
- BOURBON 范围查询表现如何?
- 在有写的情况下,BOURBON 的开销-收益分析器和其他从不重新学习的方法相比表现如何?
- BOURBON 在真实负载下的性能也能表现得和预期一致吗?
- 数据存储在存储设备上时(不再在内存) BOURBON 是否有用?
- 有限的内存的情况下,BOURBON 是否有用?
- BOURBON 在误差范围和空间开销上的权衡是怎么样的?
测试环境
硬件环境
- 20-core Intel Xeon CPU E5-2660
- 160-GB memory
- a 480GB SATA SSD
系统参数
- 16B integer keys and 64B values
- error bound - 8
- Unless specified, our workloads perform 10M operations.
负载
- 构造了四个合成数据集,64M key-value pairs
- linear, 键都是连续的
- segmented-1%, 在连续的100个键之后有一个间隙
- segmented-10% , 在10个连续的键之后会有一个间隙
- normal,从标准正态分布 N(0,1) 中抽样 64M 个唯一值,并按比例缩放到整数
- 真实负载:Amazon reviews (AR) & New York OpenStreetMaps (OSM)
测试结果
-
BOURBON 究竟优化了查询的哪些部分?
- 减少了索引花费的时间。图中标记为 Search 的部分对应基线中的 SearchIB 和 SearchDB
- 还降低了数据访问成本,因为 BOURBON 加载的字节范围比基线加载的整个块要小。
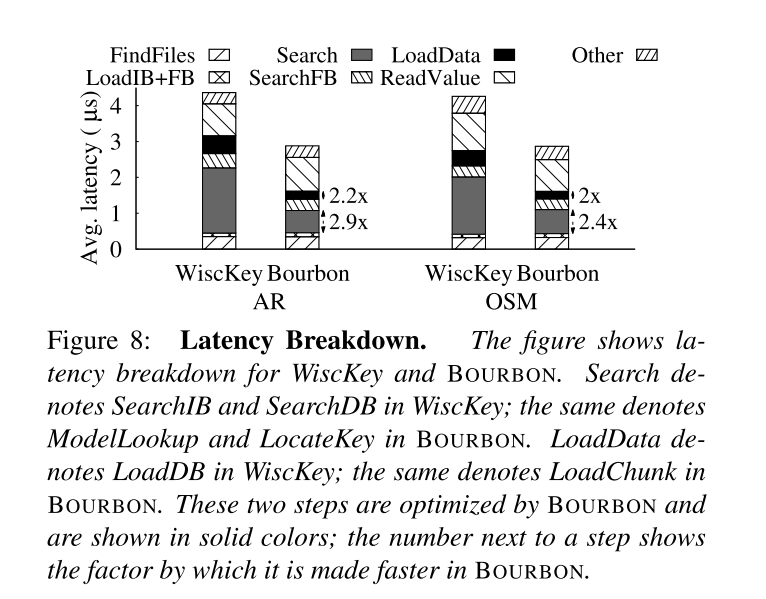
-
BOURBON 在有模型但没有写的情况下表现如何?性能会随着数据集、加载顺序以及请求分布的变化发生什么样的变化? 无论哪种情况 BOURBON 都可以提供显著的加速
- 对于所有数据集, BOURBON 比 WiscKey 更快;根据数据集的不同,提升也不同(1.23倍到1.78倍)。
- BOURBON 对线性数据集提升最大,因为它有最小的片段数(每个模型一个);使用更少的段,找到目标需要检索的段也就更少。
- 延迟随着段数的增加而增加
- level learning 适用于只读负载,BOURBON-level 比基线快1.33 - 1.92倍,比 BOURBON 更好,因为 level 学习查找对应的 SSTables 更快。
- 由于 level 模型只对只读工作负载提供好处,并且与文件模型相比最多提高10%,所以后续测试主要针对 file learning。

- 由于 level 模型只对只读工作负载提供好处,并且与文件模型相比最多提高10%,所以后续测试主要针对 file learning。
- 负载加载顺序的差异,使用顺序加载,sstable 甚至在不同的级别上都不会有重叠的键范围;然而,在随机加载的情况下,某个级别的 sstable 可能会与其他级别的 sstable 重叠。
- 无论负载顺序如何,BOURBON 都比基线有显著的优势(1.47× – 1.61×)。
- 与顺序加载情况相比,随机加载情况下的平均查找延迟有所增加。这是因为,虽然在顺序情况下没有 negative 的内部查找(10M),但在随机情况下有很多 negative 的查找(23M)
- 在随机情况下,对基线的加速比顺序情况下要小。虽然 BOURBON 同时优化了 positive 查找和 negative 查找,但 negative 查找的收益较小,因为 negative 的查询路径比较短,在 filter 处可能就终止了,没有加载或搜索数据块,而且 negative 的查询比 positive 的查询多。

- 请求的分布情况,测试了六种请求分布下的延迟,sequential, zipfian, hotspot, exponential, uniform, and latest。
- BOURBON 使查找速度比基线快1.54倍- 1.76倍。总的来说,无论请求分布如何,BOURBON 都减少了延迟。

- BOURBON 使查找速度比基线快1.54倍- 1.76倍。总的来说,无论请求分布如何,BOURBON 都减少了延迟。
- 对于所有数据集, BOURBON 比 WiscKey 更快;根据数据集的不同,提升也不同(1.23倍到1.78倍)。
-
BOURBON 范围查询表现如何?
- 如图展示了 BOURBON 的吞吐量标准化到了 WiscKey 之后的结果。对于较短的范围,索引开销(即查找范围的第一个键的开销)占主导地位,BOURBON 优化效果比较明显,但随着范围的增大,其效果就不再那么明显,这是因为BOURBON 可以加速索引部分,但它遵循与 WiscKey 类似的路径来扫描后续键。因此,在大范围查询时,索引查询占较少的总性能,性能提升就不明显了。
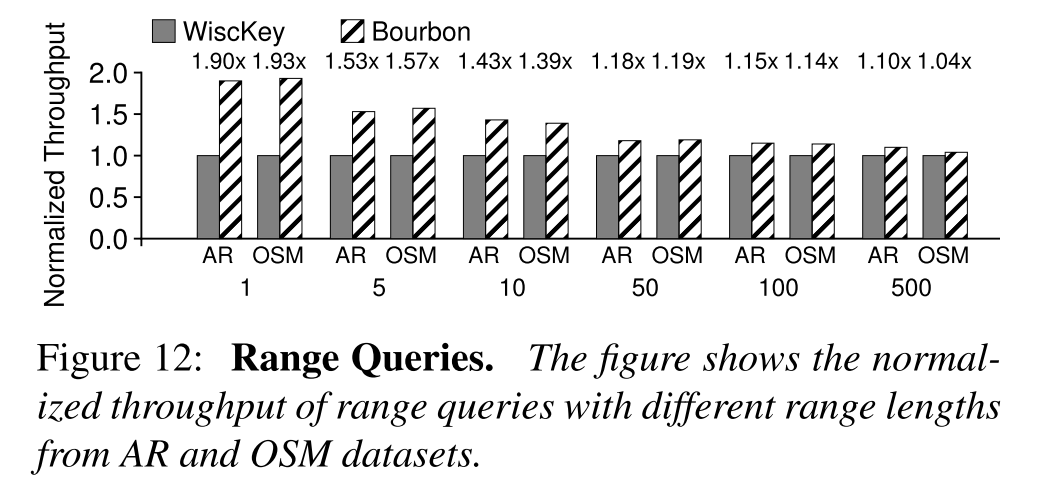
- 如图展示了 BOURBON 的吞吐量标准化到了 WiscKey 之后的结果。对于较短的范围,索引开销(即查找范围的第一个键的开销)占主导地位,BOURBON 优化效果比较明显,但随着范围的增大,其效果就不再那么明显,这是因为BOURBON 可以加速索引部分,但它遵循与 WiscKey 类似的路径来扫描后续键。因此,在大范围查询时,索引查询占较少的总性能,性能提升就不明显了。
-
在有写的情况下,BOURBON 的开销-收益分析器和其他从不重新学习的方法相比表现如何?
- 首先了解三种策略:
- BOURBON-offline 在写发生时不执行学习,模型仅针对最初加载的数据而存在
- BOURBON-always 只要写发生了就会重新学习,不考虑成本
- BOURBON-cba 会使用开销-收益分析器来决定是否学习
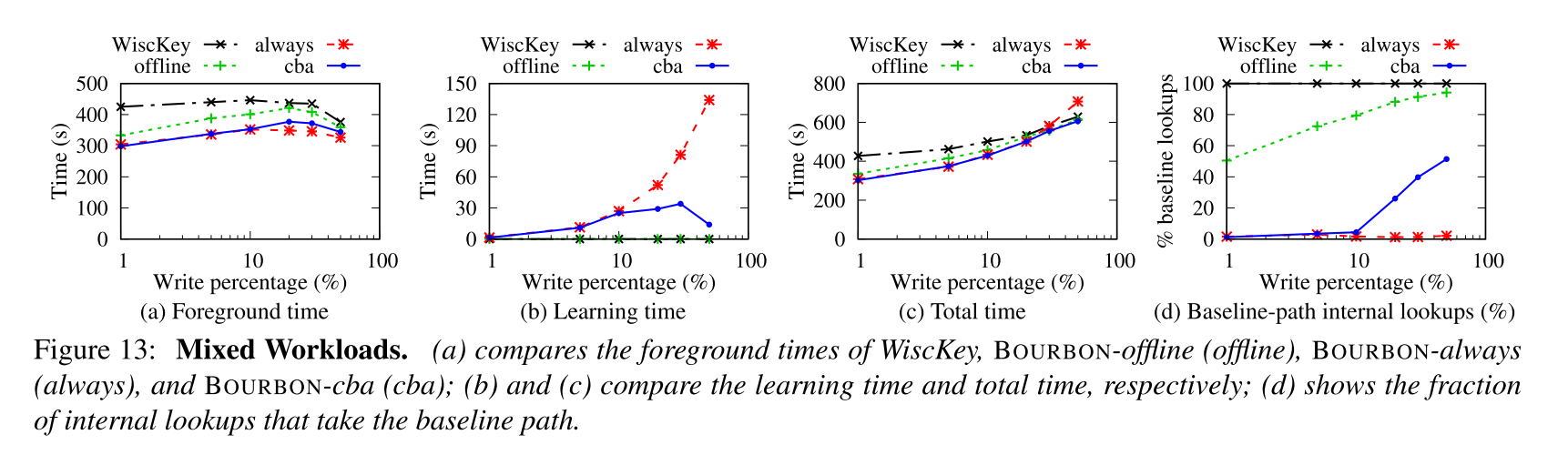
- 图 a 显示了在前端查询和插入花费的时间,图 b 显示了学习过程花费的时间,图 c 显示了总的时间开销,图 d 显示了采用基线路径的内部查找的比例
- 结果表明:
- 所有的策略都相比于 WiscKey 减少了前台任务的时间开销,随着写比例的增加,查询比例的减小,优化的效果就减弱。offline 的策略表现最差,即便是在只有 1% 的写的情况下,这时候大多都是通过基线的索引查询方式(如图 d 所示的比例)来进行,所以对于数据改变之后的重新学习十分关键
- BOURBON-always 在前台任务的时间开销上表现最好,几乎不会退化成基线的查询方式,但是对应的学习时间就特别长,在 50% 时候就大概花费 134s 进行学习,所以总的时间开销当写请求的比例较大的时候,可能比基线的时间开销还大
- 写请求比例较低的时候,BOURBON-cba 几乎会学习所有的文件,所以此时和 always 的表现比较相近,当写请求比例增大时,BOURBON-cba 不再学习特别多的文件,学习时间开销只有 13.9s,相比于 always 大大减小,因此这时候的很多查询都是按照基线对应的路径,因为此时数据变化迅速,查找次数较少,学习的收益较小。
- 总结:积极学习策略提供快速查找,但代价高昂;没有 re-learning 的话几乎不能加快速度。也不理想。相比之下,BOURBON 提供了与积极学习类似的高收益,同时显著降低了总成本
- 首先了解三种策略:
-
BOURBON 在真实负载下的性能也能表现得和预期一致吗?
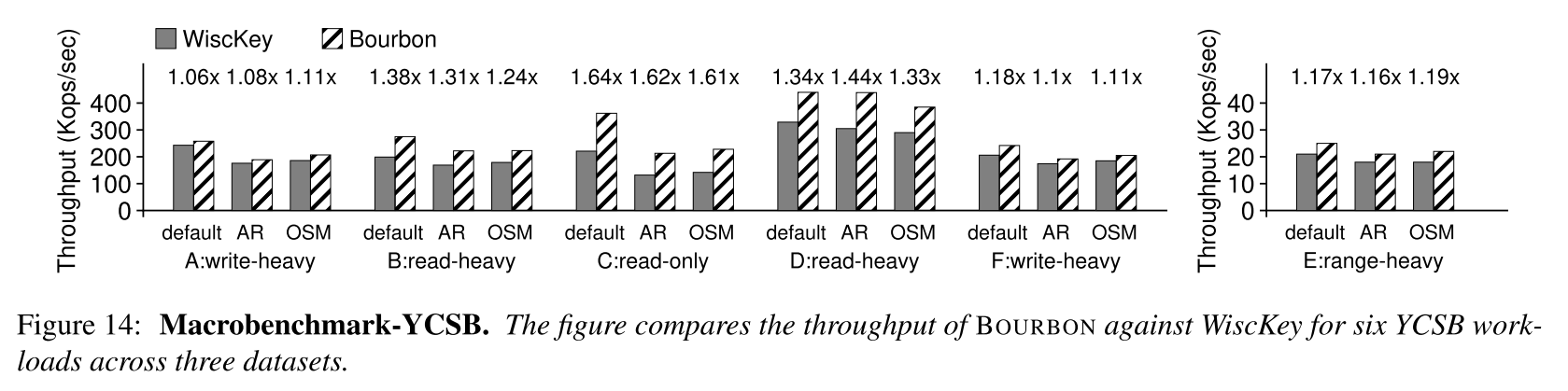
- YCSB:BOURBON 提高了读操作的性能;同时,波旁威士忌并不影响写的表现。
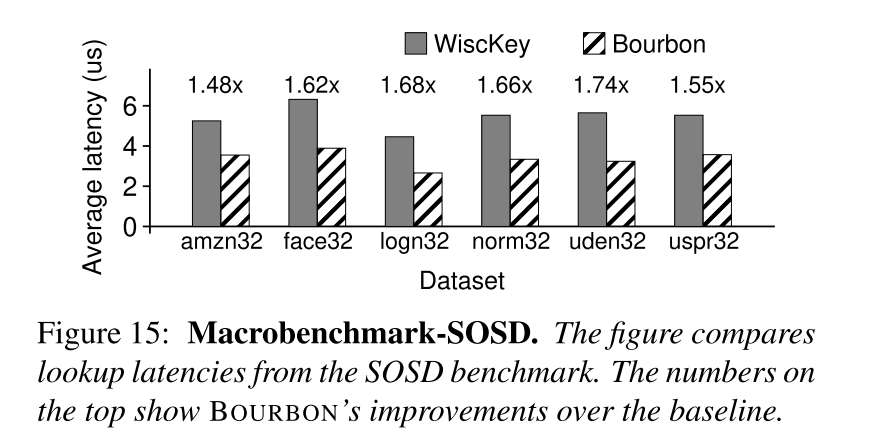
- SOSD
- YCSB:BOURBON 提高了读操作的性能;同时,波旁威士忌并不影响写的表现。
-
数据存储在存储设备上时(不再在内存) BOURBON 是否有用?
- 即使数据存在存储设备上,BOURBON 也有一定程度的提升(查询速度比WiscKey快1.25倍到1.28倍)。


- 即使数据存在存储设备上,BOURBON 也有一定程度的提升(查询速度比WiscKey快1.25倍到1.28倍)。
-
有限的内存的情况下,BOURBON 是否有用?
- 如下表所示,使用了 SATA SSD 和大小只有数据量的 25% 的内存,BOURBON 速度只有 WiscKey 的 1.04 倍,因为大部分时间都花在了将数据加载到内存上。
- 相比之下,在 zipfian 工作负载中,索引时间(而不是数据访问时间)占主导地位,因为大量请求访问已经缓存在内存中的一小部分数据,所以能够提供 1.25x 的加速和低得多的延迟。

-
BOURBON 在误差范围和空间开销上的权衡是怎么样的?
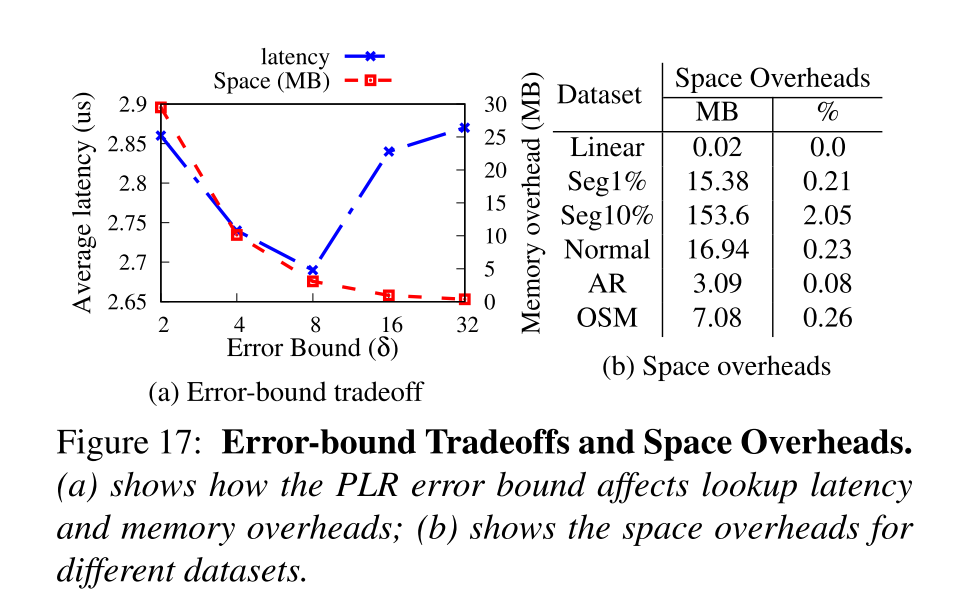
- 随着误差范围增大,更少的线段被创建,从而需要检索的线段就更少,延迟也就相应减小,然而当 δ 超过 8,尽管需要检索的分段更少,但是延迟增加了,对于其他数据集也是 δ = 8 是转折点。还显示了空间开销,因为创建的线段更少了,空间开销也就更小了。
- 对于各种数据集,开销与数据集的总大小相比是很小的(0% - 2%)。
Related Work
- Learned Index:
- XIndex
- FITingTree
- AIDEL
- Alex
- SageDB
- LSM optimizations:
- Monkey
- Dostoevsky
- HyperLevelDB
- bLSM
- cLSM
- RocksDB
- Model choices:
- Greedy-PLR
- Neural networks
- one-pass learning algorithm based on splines
