- p2KVS: a Portable 2-Dimensional Parallelizing Framework to Improve Scalability of Key-value Stores on SSDs
p2KVS: a Portable 2-Dimensional Parallelizing Framework to Improve Scalability of Key-value Stores on SSDs
Abstract
- 通过将速度较慢的硬盘驱动器(hdd)替换为速度更快的固态硬盘驱动器(ssd)来提高键值存储(KVS)性能的尝试一直未能达到ssd和hdd之间的巨大速度差距所暗示的性能提升,特别是对于小KV项目。我们通过实验和整体探索了现有基于lsm树的 kvs 运行在具有多核处理器和快速ssd的强大现代硬件上性能低下的根本原因。我们的发现表明,在单线程和多线程执行环境下,全局预写日志(WAL)和索引更新(MemTable)可能成为与常见的lsm树压缩瓶颈一样基本和严重的瓶颈
- 为了充分利用成熟KVS和底层高性能硬件的性能潜力,我们提出了一种可移植的二维KVS并行化框架,称为p2KVS。在水平的kvs -instance维度上,p2KVS将一个全局KV空间划分为一组独立的子空间,每个子空间由一个LSM-tree实例和一个固定在一个专用核上的专用工作线程来维护,从而消除了共享数据结构上的结构性竞争。在垂直的intra-KVS-instance维度上,p2KVS将用户线程从kvs -worker中分离出来,并在每个worker上提供基于运行时队列的机会批处理机制,从而提高了进程效率。由于p2KVS被设计和实现为一个用户空间请求调度器,将WAL、MemTables和lsm树作为黑盒来查看,因此它是非侵入性的,具有高度的可移植性。在微观和宏观基准测试下,p2KVS比最先进的RocksDB提高了4.6×写和5.4×读的速度。
Introduction
动机测试
- SSD 相比于 HDD 有更高的 IO 带宽 10x,更高的 IOPS x100。图1a表明,尽管RocksDB在高级 SSD 上的读性能提高了2个数量级,但它在ssd和hdd之间的写性能几乎没有变化。
- 最近的研究[19,36]和我们的实验结果一致表明,较小KV对的写工作负载会使系统的主机 CPU 核过载,而不是受到系统IO带宽的瓶颈。
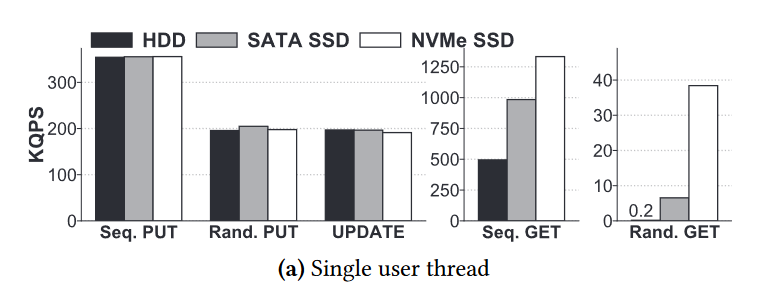
- 然而,提高处理能力的一种幼稚的方法是通过调用更多的用户线程来充分利用多核CPU的能力。图1b 显示,即使有8个用户线程,对于顺序PUT、随机PUT和UPDATE的写工作负载,每秒查询(QPS)性能也只分别提高了40%、150%和160%,远远没有达到理想的线性扩展。但是,与单线程情况相比,在写工作负载下,从基于hdd的系统到基于ssd的系统,三个8线程情况的性能提高不到10%,除了更新操作情况提高了40%。这意味着,RocksDB的设计初衷是充分利用优质SSD,最大限度地提高QPS[22],但在小型KV工作负载下仍然存在瓶颈。

相关工作
- 以前的研究表明潜在的瓶颈主要表现在 logging (SIGMOD’18 FASTER),索引(FloDB)以及 Compaction(SILK,LDC,WiscKey)阶段。
- 大量的现有 KVs 研究
- 提出了新的全局数据结构来代替 LSM(SplinterDB,SLM-DB,KVell)
- 提出了局部优化
- 缓存:LightKV,SplitKV,NoveLSM,SCM LSM,MatrixKV
- 日志:FASTER,SpanDB
- 并发索引:No Hot Spot Non-blocking Skip List,Asynchronized Concurrency,UniKV:
- Compaction:PebblesDB,LSM-trie
- 工业界也有利用硬件优势来进行优化,比如批量写入,并发跳表,多线程压缩
- 带有多个实例的KVS分片机制广泛用于公共数据库实践,以利用实例间的并行性
- HBase
- The RocksDB Experience
- Column Families of RocksDB
- RocksDB tuning guide
- Nova-LSM
- DocDB
- 现有的工作不能全面有效地解释和解决高性能硬件的性能可扩展性差。
理论分析
- 前台任务首先写 WAL,然后执行写索引,然后后台任务执行 compaction。
- 为了帮助理解成熟的kvs在快速的ssd和强大的处理器上性能低下的根本原因,我们使用经过良好优化的RocksDB进行了一系列实验(详见第3节)。结果提供了三个揭示性的发现。
- 首先,对于单个用户线程,日志记录或索引都可能造成严重的计算瓶颈,严重限制随机的小型写操作的性能。只有当日志记录和索引不再是瓶颈时,LSM-tree压缩才会成为存储瓶颈。
- 其次,增加用户线程的数量会产生一些边际效益,因为共享日志和索引结构上的争用非常多,用户线程越多,争用就越严重。
- 第三,具有多个实例的KVS分片机制仍然受到多个用户线程争用的影响,以及低效的日志记录和索引
本文贡献
- 为了克服现有 KVs 的缺陷,提出了可移植的二维并行 KVS 框架来高效利用成熟的生产环境中的 KVs 实现和底层的高性能硬件。
- 首先,水平维度,采用了一个调度方案来协调多个工作线程,每个线程专门绑定核心,维护自己的单独的 WAL 日志,Memtable,以及 LSM tree,来减小共享数据结构上的争用
- 其次,垂直层面,设计了一个全局的 KV 访问层来把用户线程和 KVs 工作线程区分开,访问层应用策略把进来的请求分发到工作队列中,进行负载均衡
- 第三,在每个worker中提出了一种基于运行时队列的机会批处理机制。对于队列中未完成的写请求,OBM 合并它们以分摊 kv 处理和日志记录的开销。对于未完成的读请求,OBM 调用现有的 multiget 功能,提高处理效率。
- 与多实例KVS配置不同,p2KVS显式地消除了实例上用户线程之间的潜在争用,同时利用批处理机制来提高效率
- 本文的目标是构建一个在 RocksDB 上的基于线程的并行框架,充分利用硬件特征同时保留它们现有的功能和内部设计,因此本文的方案是互不干扰的且非侵入式的。
- 贡献
- 我们通过实验和整体分析并确定了运行在快速ssd和多核处理器上的kvs伸缩性差的根本原因。
- 我们提出了p2KVS,一个可移植的二维KVS并行化框架,以统一有效地利用KVS实例之间和实例内部的内部并行性。我们进一步设计了一个基于队列的机会批处理机制,以提高每个工人的处理效率。
- 我们分别在RocksDB、LevelDB和WiredTiger的[49]上实现了p2KVS原型,并在流行的宏基准和微基准下进行了大量的实验来评估它。与目前最先进的基于lsm树的RocksDB和PebblesDB相比,p2KVS对小型kv的写速度可达4.6x,读速度可达5.4x。它还优于最先进的基于非lsm树的KVell。
Background
- LSM 不做介绍
RocksDB 并发优化
- 作为一个经过良好优化的基于生产级 LSM 树的KVS, RocksDB 通过利用硬件并行性实现了许多优化和配置,以提高其QPS性能。RocksDB中的并发写进程示例如图 3 所示。关键并发性优化如下:
Group Logging
- 当多个用户线程并发提交了写请求,RocksDB 将其组织成为一个组,其中一个线程被选中作为 leader 负责聚合该组内的其他线程的日志项,然后一次写入日志文件,其他线程也就是所谓的 follower,挂起直到日志文件写入完成,减少了实际的日志 I/O,因此提升了 I/O 效率。
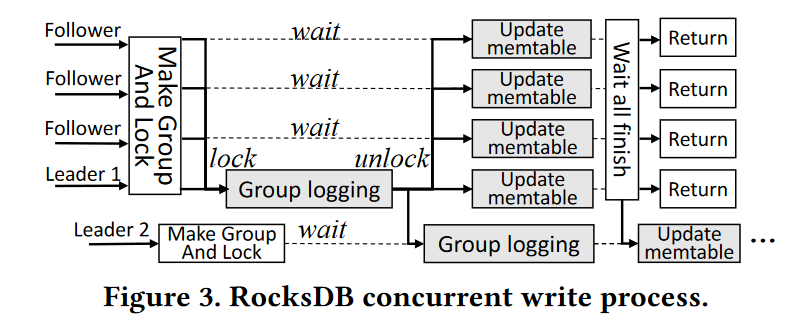
并发 Memtable
- RocksDB 支持并发跳表索引,提升 Memtable 的插入的 QPS 约 2x,像 Group Logging,在更新全局元数据时,会同步一组并发更新MemTable的用户线程
Pipelined Write
- RocksDB 把不同组的日志和索引更新步骤流水线化了来减小阻塞
- 基于 LSM 的 KVs 一般提供了请求批处理操作,也就是 WriteBatch,允许用户执行多个写类型的请求,RocksDB 将所有请求的日志记录操作合并到一个WriteBatch中,就像组日志记录机制一样。
Root Causes of Poor Scalability
单线程
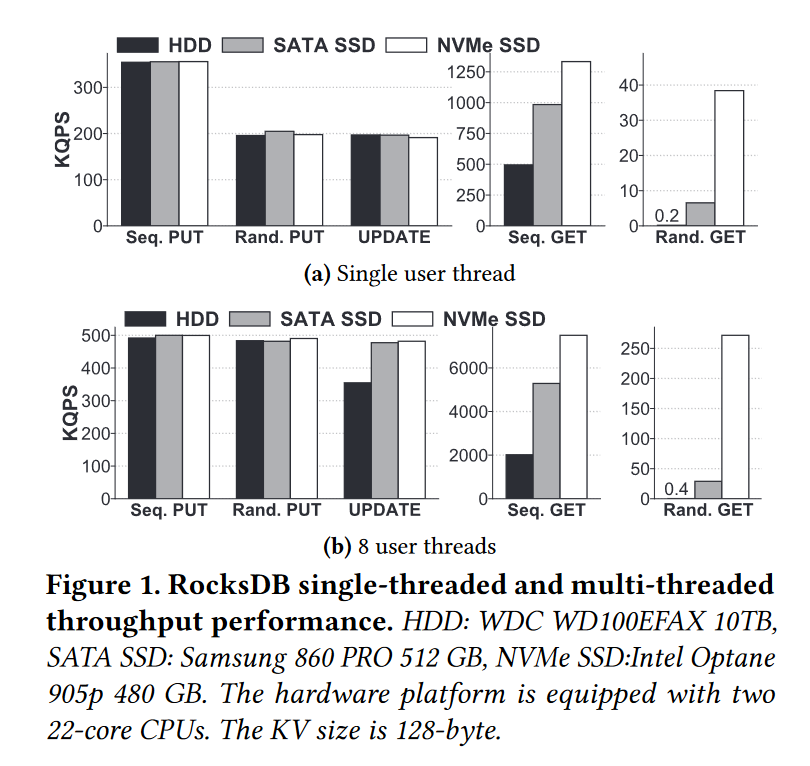
- 五组实验,128B KV,10M 条,顺序和随机写,随机 UPDATE,顺序和随机读,分别在 HDD/SATA SSD/NVMe SSD 上测试。
- 写性能没变化,读性能倒是有很大提升
- 单线程写性能表现较差,读性能较好
- 8 线程写性能表现类似
-
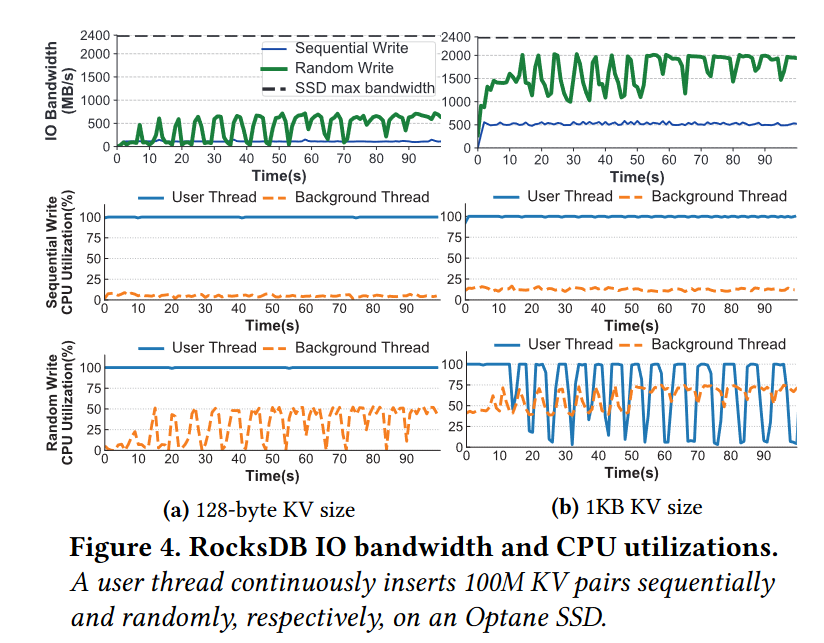
下图展示了一个用户线程插入小 KV 对应的随时间变化的性能,顺序和随机。CPU-core 利用率为 100% 的线程分别只占用 SSD IO 全带宽的 1/6 和 1/20。连续的随机写操作会触发相应的后台线程执行周期性的刷新和压缩,这些线程会消耗大约 25% 的 CPU-core 利用率。
- 现象:无论是随机写还是顺序写,无论是小 KV 还是大 KV,都远低于 SSD 的实际带宽
- 顺序写的带宽低于随机写,小KV 的带宽低于大 KV
- 随机写 大 KV 的吞吐相对最接近设备带宽
- 原因:无论是随机写还是顺序写,无论是小 KV 还是大 KV,前台线程 CPU 都接近满载
- 除了大 KV 随机写以外,CPU 基本都是满载 ****
- 现象:随机写因为受到 Compaction 的影响会有较大的性能波动
- 小 KV 随机写,后台线程大约需要使用 25% 的 CPU,前台线程 100%
- 大 KV 随机写,后台线程大约需要使用 60% 的 CPU,前台线程 70%
- 现象:大 KV 相比于小 KV 性能表现相对更好
- 原因:小 KV 的 CPU 满载的现象更严重,因为常常小 KV 意味着更多的数据条数,软件栈上的执行的请求数更多
- 现象:无论是随机写还是顺序写,无论是小 KV 还是大 KV,都远低于 SSD 的实际带宽
-
当 CPU-core 利用率约70%的用户线程连续插入随机大KV对(即1KB)时,后台线程的周期性 compaction 操作仅消耗23% IO带宽和60% CPU-core利用率,如图4b所示。
-
以往的研究大多认为LSMtree压缩是严重影响整体性能的主要因素,因为LSMtree压缩具有写停顿和写放大的高IO强度[1,3,18,41,43,46,50,54]。事实上,使用小型KV对的写工作负载会使 CPU 核过载,但IO带宽利用不足,而使用大型KV对的写工作负载则恰恰相反
- ForestDB,TRIAD,Dostoevsky,WiscKey,SifrDB,PebblesDB,LSM-trie,MatrixKV
多线程
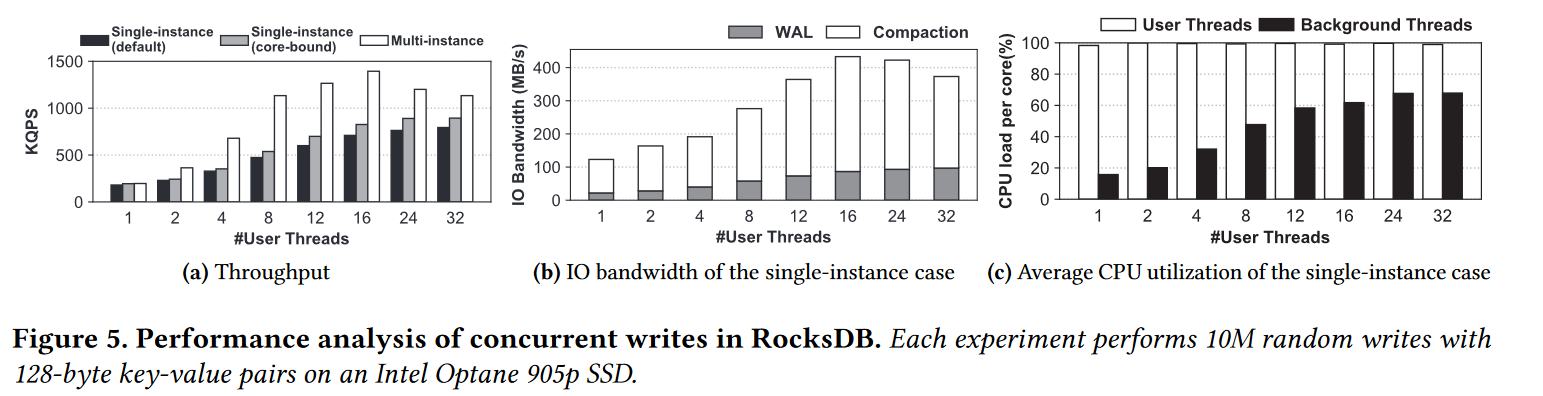
- 多核处理器和基于NVMe的ssd分别具有足够的计算能力和高并行度的IO能力。自然,利用强大的硬件增加用户线程的数量可以提高KVS的总体吞吐量。另外,在实践中,数据库从业者也可以简单地在高级硬件上配置多个独立的KVS实例,以提高整体性能。在此分析中,我们考虑由多个用户线程访问的单实例和多实例两种情况。每个KVS实例都有自己独立的日志文件、MemTable和LSM-tree。
- 下图 a 所示为扩展性,在所有并行优化的单实例情况下,写QPS的伸缩性仍然很差,在32个用户线程时只能获得微薄的 3x加速。它的吞吐量在24个线程时达到峰值,而在此之后进一步扩展则显示收益递减。与单实例情况相比,多实例情况提升80%的高吞吐量和更好的可伸缩性,其吞吐量峰值低于16个线程/实例。
- 现象:单实例,24线程达到峰值,绑核之后效果更好,多实例提升明显,且伸缩性更好,但 16 线程达到峰值
- 结论:使用多实例带来的扩展性更好,绑核也能让扩展性变好
- 现象:单实例,24线程达到峰值,绑核之后效果更好,多实例提升明显,且伸缩性更好,但 16 线程达到峰值
- 图 b 则表明 compaction 不再是瓶颈。至少不是主要的瓶颈,即便是多线程情况下。在 16 线程时达到峰值,只有 1/5 的 SSD I/O 带宽,其中 compaction 占据的带宽也不足总的 3/4。和单用户线程类似,前台用户线程的利用率接近 100%,后台线程消耗的 CPU 利用率相对较低。
- 现象:单实例,多线程写操作的 I/O 带宽远小于实际的设备带宽,其中 Compaction 开销很小,不是主要开销。
- 结论:随着并发增加,Compaction 占据的开销比例变化不大,即并发条件下,Compaction 不是瓶颈
- 现象:单实例,多线程写操作对应的前台线程 CPU 满载,后台线程随着并发数的增加 CPU 开销变大,但是也还没有到 CPU 极限。
- 结论:随着并发增加,主要瓶颈是来自于前台线程的 CPU 满载
- 现象:单实例,多线程写操作的 I/O 带宽远小于实际的设备带宽,其中 Compaction 开销很小,不是主要开销。
- 图 a 还表明了绑核能带来 10%-15% 的性能收益,因为不需要切换 CPU
处理时间
-
下图展示了不同线程在单个实例下的延迟分解,写流程分成五个步骤,WAL,Memtable,WAL Lock,Mmetable Lock and Others.
- WAL 代表写前日志的执行时间,包括 I/O 时间和其他(编码日志记录,计算校验和,以及添加到写日志的 memory buffer)
- Memtable 代表插入键值对到 Memtable,超过 90% 都是更新跳表索引信息
- WAL Lock 表示与组日志机制相关的锁开销,包括领导线程执行 WAL 时其他用户线程的锁获取时间,以及领导线程通知其他线程完成 WAL 执行的时间。
- Memtable Lock 代表同一组线程并发写 MemTable 时的线程同步时间
- 其他代表其他软件开销
-
锁开销:随着写入器数量的增加,WAL 和 MemTable 的 CPU 周期百分比从单个线程时的 90% 下降到 32 个线程时的16.3%,而总锁开销(即WAL锁和MemTable 锁)从几乎为零增加到 81.4%。更多的写入器会对共享数据结构(如日志和MemTable)引入更严重的争用。特别是,只有 8 个线程的 WAL-lock 占用了一半以上的延迟。根据 Amdahl 定律,在小型KV对的高并发工作负载下,对特定日志和索引结构的优化不再有效,因为序列化瓶颈占延迟的较大比例。
-
造成高锁开销的主要原因有三个。首先,
- RocksDB 的组日志策略由 leader 进行日志写入序列化的操作,并挂起follower;
- 第二,组中的线程越多,用于解锁 follwer 线程的 CPU 时间就越多;
- 最后,将多个线程插入到MemTable中会带来同步开销。
-
现象:单实例,随着线程数增加,延迟也不断增加,其中加锁操作带来的开销比例也不断增加
- 原因:因为涉及到跳表并发写的同步操作,以及 Group Logging 的同步操作,线程数增加,争用越大,延迟越高

Multi-threading, a Double-edged Sword
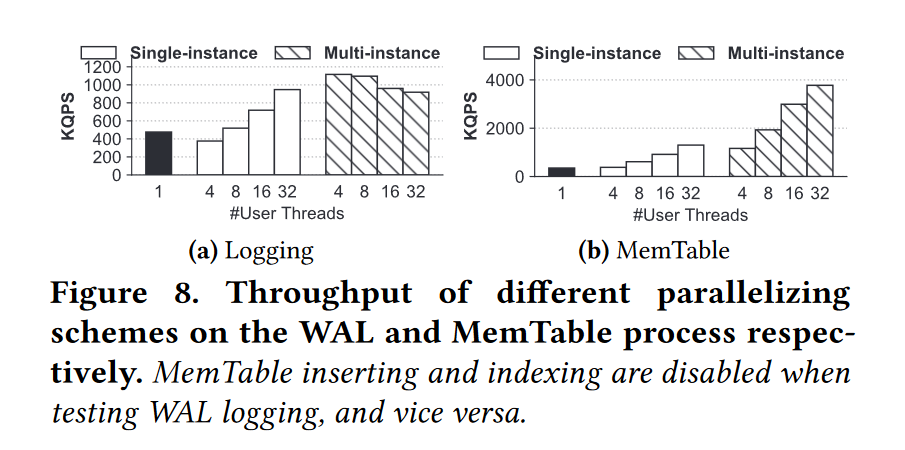
- 如上所示的实验结果表明,多线程在利用并行性方面的优势可以被线程之间在共享数据结构(如日志和索引)上的争用所抵消。因此,应该找到一个谨慎的权衡,以达到最佳的整体结果。考虑到这一点,接下来,我们将研究多线程对日志记录和索引这两个关键瓶颈的影响。我们实验分析了128字节KV工作负载下WAL进程单实例和MemTable进程多实例的性能,如图8所示
WAL
- 如图6所示, WAL 的平均延迟降低从一个用户线程 2.1微妙到在 32 个用户线程 0.8 微妙。这是因为分组日志策略将来自不同线程的小日志收集到更大的IOs中,从而提高了IO效率。
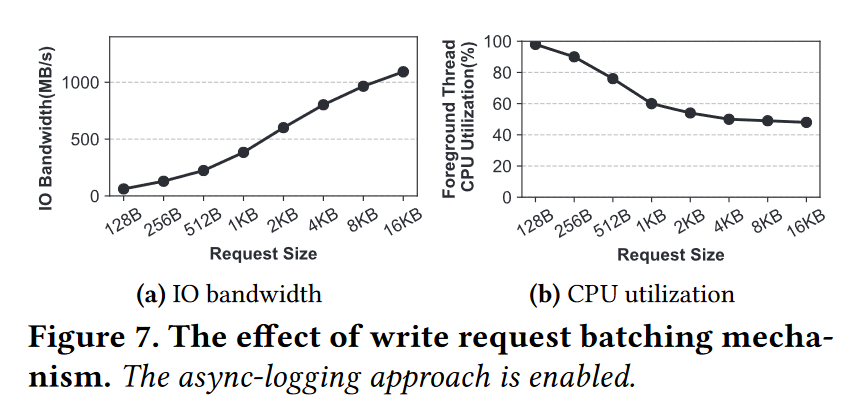
- 为了演示批处理机制对写性能的影响,我们在将几个128字节的键值对批处理为 256 字节到 16KB 大小的WriteBatch请求时,测量了WAL的带宽和CPU使用情况,如图7所示。在RocksDB的默认配置中,启用了RocksDB的异步日志记录方式,以消除每次小IO后由于fsync引起的写放大。结果表明,请求级批处理机制不仅可以通过IO大小提高SSD的带宽利用率,还可以通过IO栈中软件开销的减少有效降低CPU负载
- 现象:更大的 writebatch,更高的 I/O 带宽利用,更高的性能,更低的 CPU 利用率
- 原因:因为更大的 batch,节省更多的小 I/O 造成的写放大,因为 I/O 更大,也减小了 I/O 栈上的软件开销,CPU 开销也就降低
- 结论:使用 Batch 机制有利于改进性能,并提升 I/O 带宽利用,降低 CPU 开销
- 图8a显示,使用批处理的单实例情况下,如果有32个线程,QPS提高了 2x,而多实例情况下,如果有4个线程,QPS的峰值超过 2.5x QPS。底层SSD中有限的IO并行性在很大程度上决定了多实例情况下日志记录线程的最佳数量
Index
- 不同于上面的记录过程中,总体吞吐量MemTable索引更新过程中的尺度在单实例和多实例的情况下,如图8 b所示
- 虽然更新的延迟 MemTable 增加从单个线程2.9微妙到 32 线程的 5.7 微妙。而且,多实例的情况明显优于单实例的情况。具体来说,在图8b中,前者在32 线程时吞吐量增益达到 10.5xQPS,而后者在 32 线程时仅提高了 3.7xQPS。这种性能差距主要源于同步开销和后者中共享并发 skiplist 的收益递减。这表明,尽管并发的 MemTable 允许多个线程并行地插入到 skiplist 中,但其可伸缩性是有限的。
- 综上所述,单实例和多实例情况在使用高性能硬件部署到当前KVS架构时,都显示出了各自在可伸缩性方面的优势和劣势。
- 对于WAL日志瓶颈,虽然单实例情况可以通过利用批处理机制而始终受益于线程伸缩,但多实例情况可以获得更高的日志吞吐量性能,但实例间的并行性有限。
- 另一方面,在多实例情况下总体索引更新性能比在单实例情况下更好,因为在前者中没有锁争用。
- 此外,由于WAL和MemTable位于同一个KVS写关键路径上,在进程流中,前者位于后者之前,因此总体吞吐量受到两个进程中较慢进程的限制。这些观察和分析表明,充分利用底层高性能硬件的KVS处理体系结构的设计应该全面考虑实例间和实例内并行性、日志记录和索引之间以及计算和存储开销之间的相互作用和权衡
- 现象:单实例多线程以及启用 batch 能够带来写日志的性能提升,但不如多实例。多实例下 WAL 性能也会受到器件本身的并行性的影响
- 结论:只使用 batch 的单实例多线程方案虽然能带来 WAL 的性能提升,但不如多实例
- 实例内的并行性是不够的,还需要考虑实例间的并行性。
- 现象:单实例多线程以及启用 batch 能够带来写 Memtable 的性能提升,但不如多实例。多实例优势更明显
- 结论:只使用 batch 的单实例多线程方案虽然能带来 Index 的性能提升,但不如多实例
Design and Implementation
- 在前几节中,我们深入的实验分析促使我们提出了一个可移植的二维并行KVS框架,称为p2KVS,以有效地利用成熟的产品KVS实现(如RocksDB)和现代硬件的力量。p2KVS采用了以下三方面的设计方法。
- 利用实例间并行性,在多个KVS实例之间进行水平键空间分区。p2KVS采用多个KVS-worker线程,每个线程绑定在不同的核上。每个worker运行一个KVS实例,带有自己独立的WAL日志、MemTable和LSM-tree,从而避免共享数据结构上的争用
- 使用全局KV访问层公开实例内部并行性。p2KVS设计了一个全局KV访问层,将用户线程和kvs工作线程分开。接入层将来自应用程序的所有KV请求策略性地分配到worker队列,在有限数量的worker之间实现负载均衡。
- 使用基于队列的机会批处理来缓解日志记录和索引瓶颈。p2KVS在每个worker中提供了一种基于运行时队列的机会批处理机制,以分摊kv处理和日志记录的开销。
Arch
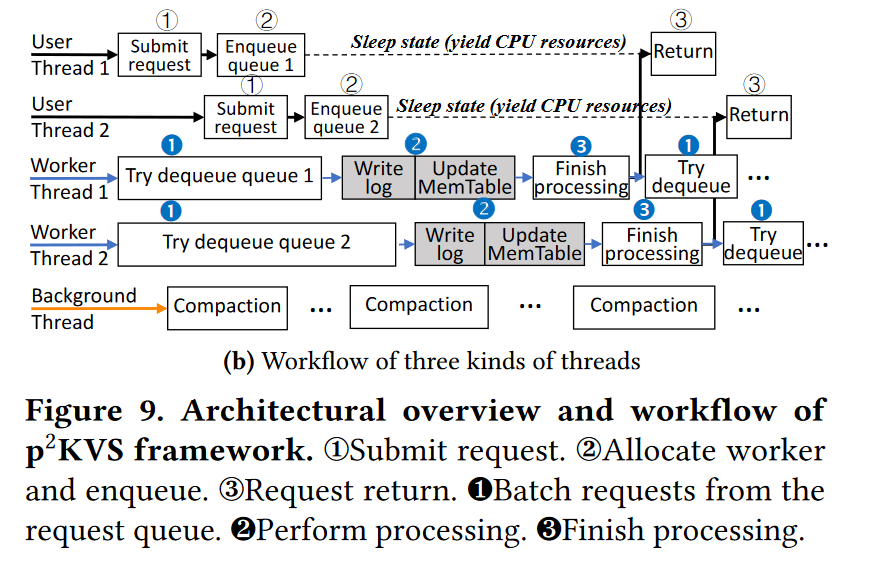
- 垂直维度多了一个访问层,水平维度维护了一组工作线程,每个线程跑一个 LSM 实例,且有自己的请求队列,绑定核心。
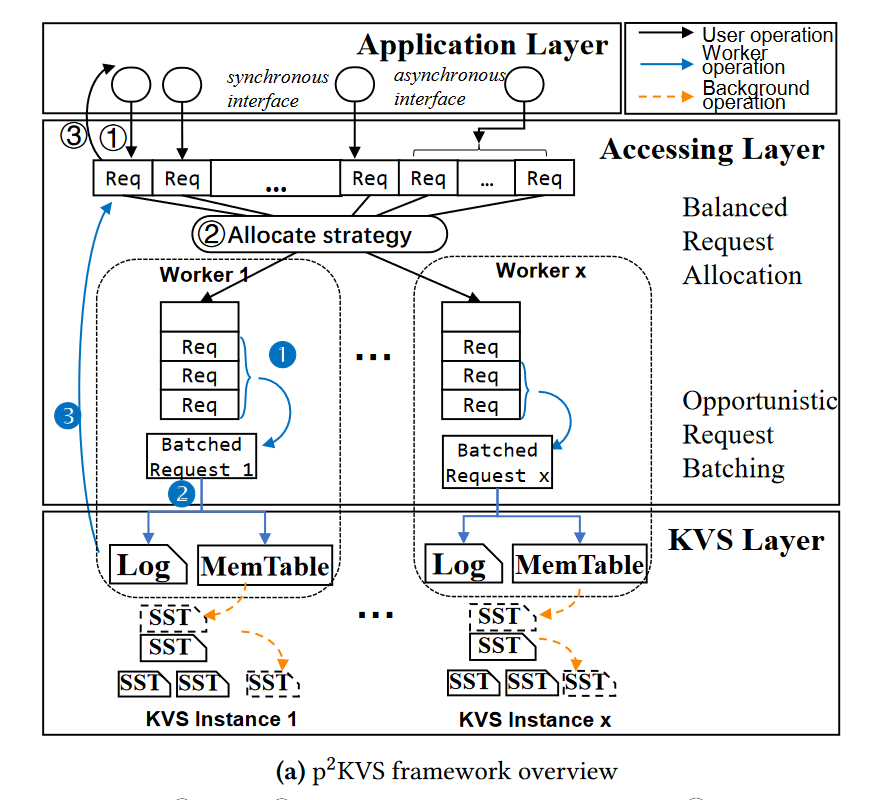
- 每个用户线程处理分配给自己的请求。
- 每个用户线程只根据分配策略将请求提交到相应 worker 的请求队列中 (1),
- 然后挂起自己而不会进一步消耗 CPU (2)
- 工作线程
- 批量处理入队请求 【1】
- 在对应的 KV 实例中执行 【2】
- 请求处理结束【3】
- 挂起的拥有线程将被通知返回(3)
- 请注意,请求处理会消耗worker的CPU资源。RocksDB中的主要和次要的压缩操作是由属于KVS实例的后台线程执行的。这些实例内并行性优化依赖于KVS实例的实现,而p2KVS与它们完全兼容
- p2kv维护一个全局标准KV接口,如PUT、GET、DELETE、SCAN等,并期望对上层应用程序完全透明。但是,它将KV请求重定向到内部分片的KVS实例,提供了实例间的并行性。请注意,虽然数据库和应用程序通常利用用户特定的语义(例如,RocksDB[20]的列语义)来为底层的多个KVS实例分配键值对,但p2KVS为上层应用程序提供了标准的KV接口,而没有额外的语义。此外,p2KVS还扩展了异步写接口(例如, 𝑃𝑢𝑡 (𝐾, 𝑉 , 𝑐𝑎𝑙𝑙𝑏𝑎𝑐𝑘))), 一个用户线程不会被正在处理请求阻塞。
Balanced Request Allocation
- 为了公平分配和调度,本文用了简单的基于取模的哈希函数来实现,对键 Hash 然后取模对应的 worker 数,的到线程 ID。worker 数的设定是根据测试的硬件的并行性来设定的,根据原文的硬件测试结果设置为了 8。基于哈希分区的优势:负载均衡,最小的开销,没有读放大(分区之间没有键重叠)
- 增加 worker 数或者调整哈希函数可能导致重新构建 KV 实例,可以考虑采用一致性哈希。我们的实验结果表明,即使在使用Zipfian分布的高度倾斜的工作负载下,散列函数仍然可以使热请求均匀地分布在各个分区上。由于实例之间存在不平衡的可能性,例如,大多数热请求偶尔会被散列到某个worker上,p2KVS 在单个实例下被降级为 RocksDB。此外,p2KVS 可以配置适当的分区策略,以很好地匹配工作负载的访问模式,例如使用多个独立的散列函数 (DistCache)或动态键范围(NovaLSM)
- 注意,这个键范围分区相当于用多个互斥子键范围扩展全局 lsm 树中每一层的容量。因此,分区可以在一定程度上减少 compaction 导致的写放大,因为多个实例增加了LSM-tree的宽度,同时降低了它的深度
Opportunistic Request Batching
-
如3.4节所示,对于小的写操作,请求批处理是减少IO和CPU开销的有效方法。此外,一些kvs(如RocksDB)对读类型请求有很好的并行优化。这些特性有助于提高每个 worker 的整体表现。
-
为了提升内部并行性,引入一个基于队列的请求批处理调度技术,简称 OBM,如下图所示。
-
当工作线程处理请求时,用户线程将请求添加到请求队列中。当worker完成一个请求的处理后,它会检查请求队列。如果有两个或更多连续的相同请求类型的传入请求(例如,读类型GET或写类型PUT、UPDATE和DELETE),它们将合并成一个批处理请求,然后作为一个整体处理,如算法1所示。

-
对于写类型的请求,工作者将其作为WriteBatch处理。与 IO 级别的批处理(如RocksDB组日志记录)相比,这种请求级别的批处理更有利于减少线程同步开销。
-
对于读类型的请求,工作人员在KVS上并发查询它们。RocksDB提供了一个multiget接口,这是一个非常优化的操作来处理内部并发的键搜索,我们在实现中使用这个接口来处理读类型的批处理请求。
-
注意,worker 不会主动等待来捕获传入的请求。因此,这种批处理是机会主义的
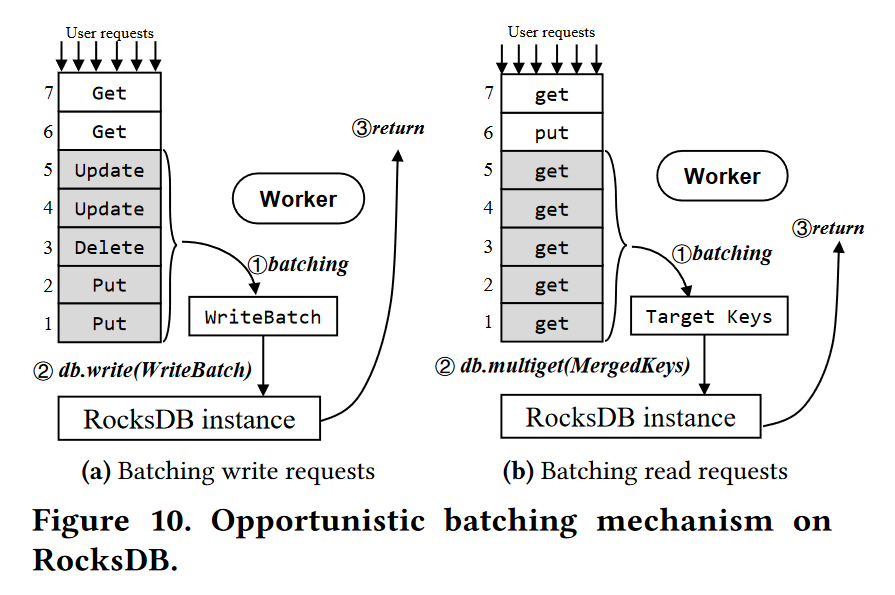
- OBM 可以通过消除同步和等待的开销来提高高并发工作负载下的处理效率。为了防止由于非常大的批处理请求而导致的尾延迟问题,我们为每批处理的请求数设置了预定义的上限(默认为32)。虽然不同类型的请求也可以在一个实例中并行处理,但OBM只会连续地合并相同类型的请求,以避免在使用异步接口时由于无序读写请求而导致的一致性问题。当队列在较低的工作负载下通常为空时,该方法只是降级为KVS,而不需要批处理。
- 总之,p2KVS 使用 OBM 机会主义地将多个小请求聚合为一个更大的请求,这不仅减少了写进程的软件和日志 IO 开销,而且还利用了并行读优化。与RocksDB 或其他 kvs 中的IO级批处理机制不同[SpanDB, KVell],p2KVS避免了在底层IO层合并写操作时引入额外的同步开销。
Range Query
- 像其他使用哈希索引的 KVS 一样,p2KVS 实现范围查询操作(即 range 和 SCAN )是一个挑战,因为相邻的键可能被物理分布到不同的实例。键空间分区意味着一个范围查询必须被 fork 到对应的 worker 中,覆盖指定的键范围。幸运的是,每个分片实例使用自己的 LSM-tree 结构来保持其内部键的排序,有利于范围查询。
- RANGE和SCAN之间存在语义上的差异,导致它们在p2KVS中的实现存在一些差异。RANGE 操作指定一个开始键和一个结束键,并读出它们之间所有现有的 KV 对。不同的是,SCAN 操作指定了一个开始键和随后要读取的KV对的数量(即扫描大小)。
- 当底层IO带宽足够时,一个RANGE请求可以被分成多个子RANGE操作,由多个p2KVS实例并行执行,而无需额外的开销。
- 对于SCAN操作,请求的键在实例中的分布最初是未知的,因此每个KVS实例中的目标键的数量不是先验确定的。
- 保守的方法是构造一个全局迭代器,基于每个KVS实例的迭代器,串行遍历整个密钥空间中的密钥,类似RocksDB MergeIterator。
- p2KVS还提供了另一种并行化方法,它首先在所有实例上使用相同的扫描大小执行SCAN操作,然后从所有返回值中过滤出请求的kv。这种方法会导致额外的读取,可能会影响性能。
- 然而,实现的简单性和易用性以及底层硬件提供的高带宽和并行性可以合理地证明它的使用是合理的。
崩溃一致性
- p2KVS 保证了与底层 KVS 实例相同级别的崩溃一致性,每个实例都可以在崩溃或失败后通过重放自己的日志文件来恢复。
- 大多数基于lsm树的 KVS 支持基于 WriteBatch 的基本事务,其中同一个事务中的更新由一个 WriteBatch 提交。当一个包含多个实例的事务被执行时,该事务被拆分为多个并行运行在这些实例上的 writebatch,如果在崩溃前只提交了其中的一部分,就会导致一致性问题。
- 为了解决这个问题,p2KVS 为每个写请求引入一个严格递增的全局序列号(GSN),以表明其唯一的全局顺序。GSN 可以作为原始日志序列号的前缀写入KVS日志文件。从同一个事务中分离出来的 writebatch 具有相同的 GSN 号,OBM 不会将它们与其他请求合并。
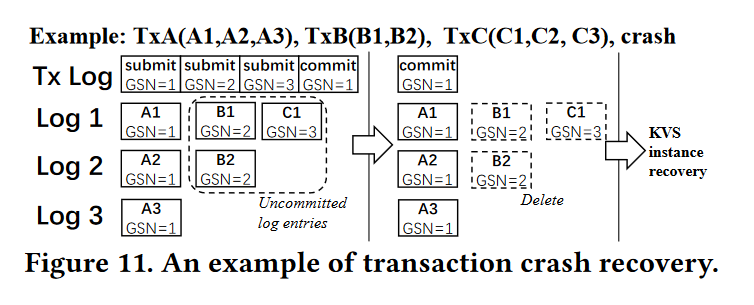
- 当一个实例崩溃时,p2KVS 根据崩溃实例日志中的最大 GSN 回滚所有实例中的日志记录请求。为了确保系统崩溃后的恢复,当事务初始化或提交时,p2KVS 将事务的 GSN 持久化到 SSD 上,从而在崩溃后通过取消每个 KVS 实例上相应的 WriteBatch 来回滚整个事务。例如,在图 11 中,在崩溃之前,事务A已经返回并记录了提交,事务B已经被kvs处理但没有提交,事务C还没有完成。当系统恢复时,p2KVS首先删除事务B和事务C的日志记录,因为事务日志显示最后一个提交的事务的GSN是事务A,然后对所有KVS实例执行恢复过程。我们进行了在写数据时杀死p2KVS进程的实验,结果表明p2KVS总是可以恢复到一致的状态。
- 目前,p2KVS专注于扩展基本KVS操作的性能(例如,批写和读),在不修改底层KVS代码的情况下,确保任何单个请求在高并发下的原子性和崩溃一致性。在未来的工作中,我们将采用现有的事务优化[37,48],并通过进一步利用KVS代码中的功能来支持更多的事务级别。例如,p2KVS可以使用RocksDB的快照特性来实现读提交事务隔离级别。每个worker都在WriteBatch处理之前创建一个实例的快照,其他读请求将访问该快照以避免脏读。当事务提交时,快照将被删除,事务中的更新将变得可见
Portability
- p2KVS 作为一种可移植的并行化框架,可以灵活地应用于现有的 kvs。本节描述p2KVS在两个代表性的kvs上的可移植性实现,即LevelDB(基于lsm树)和WiredTiger(基于B+树)。两者都使用WAL机制和共享索引结构
- 因为所有kvs都有三个基本功能,即初始化、提交请求和关闭。p2KVS将自己的逻辑插入目标KVS的这三个函数中,保持相应的API和进程不变。
- 在初始化步骤中,p2KVS创建多个实例和目录,在KVS的开放函数中存储它们自己的数据。
- 在请求提交步骤中,用户线程调用KV请求(例如put和get),并执行分配策略将请求插入到相应实例的队列中。实例 worker 从请求队列中获取头部请求,并调用相同的KVS API(例如put和get)来处理KV操作。如果KVS具有批处理请求的专用功能,如RocksDB的Writebatch和multiget,则可以相应地启用OBM机制。
- 当p2KVS关闭时,每个worker调用KVS的close API。此外,任何worker崩溃都会导致整个系统关闭
- p2KVS 的 OBM-write 功能可以在 LevelDB 上通过批写来执行,而在 WiredTiger 上没有批量写。尽管LevelDB和WiredTiger没有像multiget那样的批读功能,p2KVS仍然可以利用OBM并发提交多个读请求来利用内部并行性。5.6节的实验结果表明,p2KVS可以有效提高LevelDB的并行度,WiredTiger的读写速度明显加快。
Evaluation
- 我们以最先进的kvs(包括基于LSM-Tree的RocksDB和PebblesDB,以及基于Btree的KVell)为基准,在微基准和宏基准上评估了一个基于RocksDB的p2KVS原型。PebblesDB[46]是一种典型的写优化解决方案,它减少了压缩的写放大。KVell[36]通过使用非竞争的工作线程维护多个b -树索引来利用线程级并行性(详细信息请参见5.5节)。我们还在5.6节中评估了LevelDB和WiredTiger版本的p2KVS,以证明其可移植性。
实验配置
- 我们在使用两个Intel Xeon E5-2696 v4 cpu (2.20 GHz, 22核)、64 GB DDR4 DRAM和一个Intel Optane 905p 480 GB NVMe SSD的服务器上运行所有实验。Optane SSD具有高且稳定的读写带宽,分别为2.2 GB/s和2.6 GB/s。我们使用带有4个或8个 worker 的两种p2KVS配置,分别标记为p2KVS-4和p2KVS-8。
- 我们使用微基准来比较p2KVS和基线的峰值处理能力。我们使用带有16个用户线程的db_bench工具执行 100M 个随机PUT操作,以评估并发写性能。p2KVS的异步接口使能,显示峰值性能。我们还分别执行10M的GET操作和1M的SCAN操作来评估读性能。在macro-benchmarks,我们使用 YCSB 来生成合成工作负载,其主要特征是表1中总结。我们分别在8个和32个用户线程的2组实验中评估了强并发和弱并发的性能。在两个基准测试中,KV对的大小默认设置为128字节
Micro
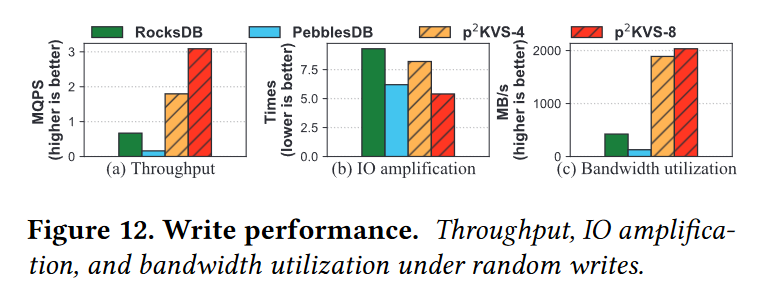
- 写性能、IO 放大、带宽利用率
- 虽然PebblesDB优化了 Compaction,IO放大比RocksDB和 p2KVS-4 低,但由于它是基于LevelDB开发的,没有对并发写进行优化,因此IO放大比p2KVS-8高。p2KVS几乎充分利用了SSD的带宽,而RocksDB和PebblesDB的带宽利用率不到20%。这是因为p2KVS通过消除前端瓶颈更频繁地触发压缩。显然,p2KVS的性能优势来自于它对底层硬件的高效容量利用
-
在表2中,我们展示了在p2KVS和其他kvs上处理100M随机写操作时内存和cpu的使用情况。
-
在所有kvs中,平均内存使用量小于1.5 GB。p2KVS-4和p2KVS-8的CPU消耗分别超过单核的 7x和12x。
-
p2KVS的这些较高的CPU使用率来自于4或8个工作线程和额外的后台线程。用户线程在提交请求后休眠,只消耗很少的CPU资源。
-
RocksDB中的每个用户线程都会重载几乎整个CPU核,导致16个线程时巨大的CPU占用。然而,由于频繁的线程同步和锁开销,它的吞吐量很低。因此,后台压缩线程占用的CPU资源较少。
-
因为PebblesDB没有针对并发写进行优化,所以大多数并发用户线程都处于等待状态,只占总CPU资源的一小部分。
-
p2KVS的内存消耗来自底层RocksDB实例的内存使用总和。这是可以接受的,也是稳定的,因为RocksDB实例的内存使用量不会随着数据量的增加而增加
-
-
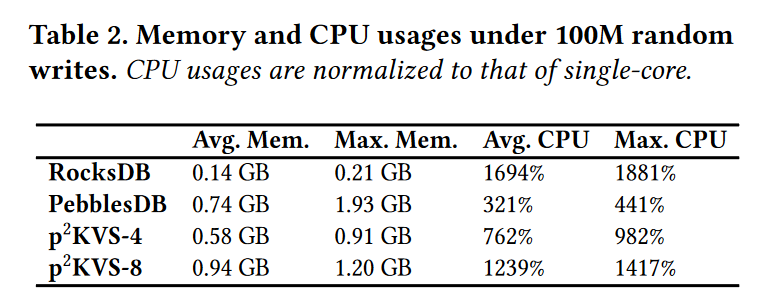
接下来,我们评估请求延迟作为负载强度的函数。我们在RocksDB和p2KVS上以不同的请求强度进行1M随机写操作。图13a显示了p2KVS和RocksDB在轻负荷下的平均延迟非常接近。
- 然而,由于p2KVS具有更高的处理能力,它可以在相同的延迟下支持比RocksDB更高的强度。
- 我们进一步观察了尾部延迟,这是衡量KVS用户体验质量的一个重要指标。如图13 b, RocksDB遭受剧烈的延迟当请求峰值强度超过100 KQPS,而p2KVS能保证99푡百分比小于400 KQPS延迟低于1 ms的强度。
-
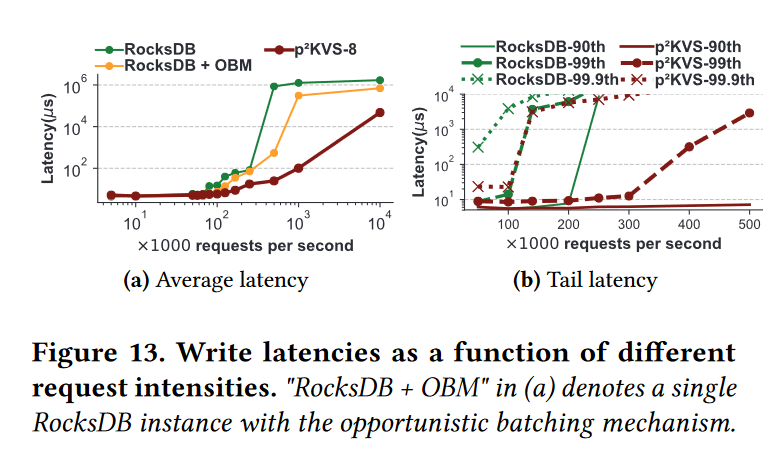
下图展示了多个 workers 和 OBM 下的点查询性能。我们向RocksDB和p2kv发起10M GET请求。
-
如图14a所示,在没有OBM的情况下,p2KVS的性能与RocksDB基本相同。
-
通过利用RocksDB和OBM p2KVS的读优化,可以实现几乎线性的可伸缩性,如图14b所示。启用OBM的p2kv -8的QPS比禁用情况高出7.5倍,RocksDB高出5.4倍。
-
-
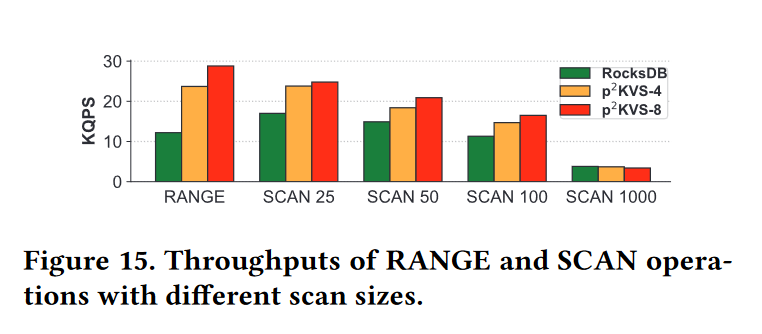
范围查询。我们加载100M 128字节KV对对系统进行预热,然后使用单个用户线程执行不同扫描大小的1M RANGE或SCAN操作。如图15所示,在RANGE查询中,
- p2KVS比RocksDB高出2.9个百分点。p2KVS在小范围扫描期间将QPS提高1.5倍,因为有足够的IO带宽来补偿读放大。短扫描的性能取决于查找操作,p2KVS对随机读的并行优化也加快了查找操作,从而提高了短扫描。
- 当扫描大小大于1000时,读放大倍数较高的p2KVS会使SSD IO容量饱和,性能与RocksDB相同。综上所述,p2KVS在RocksDB读优化的基础上进一步扩展了并行性的好处
Macro-benchmark
- 我们评估了p2KVS相对于RocksDB在具有8或32个线程的YCSB工作负载下的有效性,如图16所示。PebblesDB的结果被排除在外,因为它填满了所有的内存,并且在写入数亿KV对时崩溃。
- 在写密集型工作负载(LOAD)下,有更多的用户线程,p2KVS表现出更高的速度。例如,p2KVS8在8个和32个用户线程的情况下,比RocksDB的性能分别高出2.4和5.2。这是因为p2KVS不仅集成了RocksDB的OBM请求级批处理优化,而且还通过多个非竞争worker提高了并行效率,特别是在高并发工作负载(如32线程)下。p2KVS-8的性能提升比p2KVS4更明显,说明worker的数量应该与硬件并行度相匹配,才能使性能最大化
- 在读密集型工作负载(B、C、D)下,p2KVS比RocksDB提高了1~2xQPS。这种读性能的提高不仅来自于使用OBM来利用RocksDB原来的读并行性,还来自于哈希分区索引和并行工作者的额外好处。在工作负载E(即95% SCAN和5% PUT)下,p2KVS的性能与RocksDB类似,因为p2KVS利用IO并行性所获得的增益被读取放大所抵消。
- 在混合工作负载(A, F)下,p2KVS的性能比RocksDB高出1.5~3.5,主要是因为对并发写过程进行了优化。
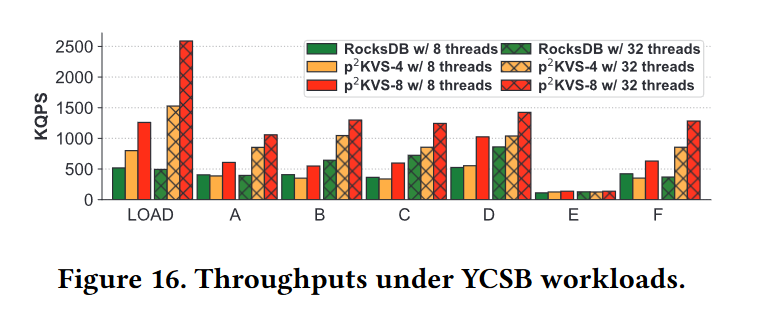
Sensitivity Study
- 我们进行敏感性研究,以了解不同设计参数和p2KVS的选择对整体性能的影响。我们仍然使用YCSB作为工作负载,并使用带有单个用户线程的RocksDB作为基线。
worker 数量和OBM
- 我们改变启用和禁用OBM的 worker 数量。结果如图17所示。在写密集型工作负载LOAD下,实例间并行性可以分别用4个和8个实例提高3x和5x性能。OBM利用请求批处理进一步加快了写速度,使QPS最多提高了2x。结果表明,在小型kv的情况下,仅仅增加实例的数量并不能显著提高性能。但是,当应用OBM时,写吞吐量可以很好地扩展。
- 在读密集型工作负载C下,实例间并行化将性能提高了3.3x和5.8x,分别为4个和8个worker。OBM甚至在单个实例中提高了5x读性能,但在8个worker中只能提高2xQPS,因为这种级别的并行性几乎耗尽了SSD的容量,导致OBM进一步利用的带宽不足
- 在混合工作负载A和B中,如果没有OBM,在4个实例和8个实例下,总体性能分别提高了3.5x和6.5x。OBM在工作负载B下增加了2.2 ~4.2x的QPS,而在工作负载A下获得的好处较少,增加了1.8 x~3.2x的吞吐量。这是因为工作负载B有更多的混合读和写请求,限制了OBM的批处理大小,OBM只批处理相同类型的相邻请求
- 由于SSD的争用,过多的worker甚至会导致性能下降。图17的实验结果表明,8是最优 worker 数量。
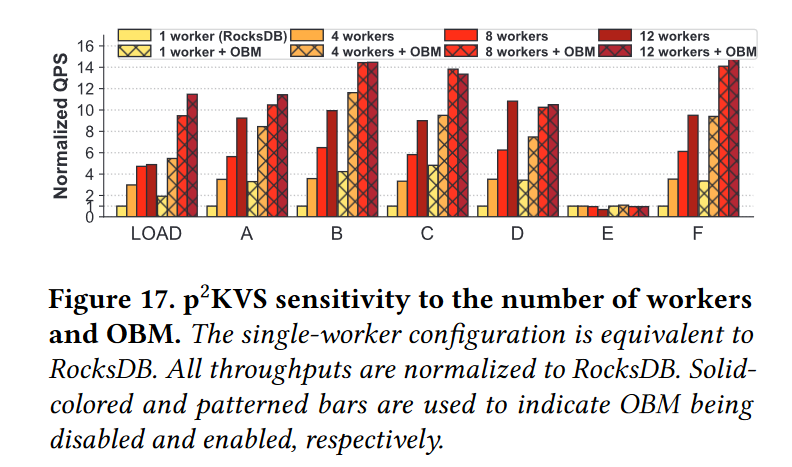
Key-value Size
- 接下来,我们观察不同KV尺寸的影响。我们在三个典型的工作负载(LOAD、a和C)中测试kv大小的性能,如图18所示。计算结果表明,小KV 比大 KV 从 OBM 中获得的收益更多。
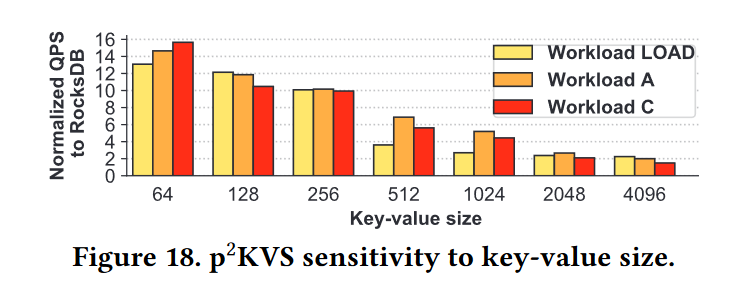
- 图19 显示了 p2kv 在1KB KV下的性能,其速度比128字节KV下的速度要慢。OBM在大KV的写密集型工作负载下效率较低,因为合并大型日志IOs的好处很小。但是,OBM对于读密集型工作负载仍然有效。
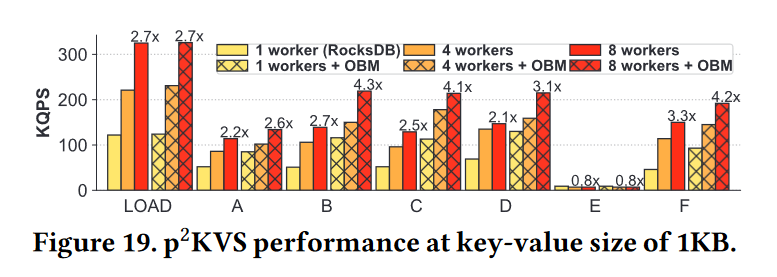
对比 KVell
- KVell 使用多个worker来维护多个可以并行访问的独立 b 树索引。它对所有写请求使用就地更新,以避免写放大,并在内存中维护大索引和页面缓存,以加快查询。
- 通过使用宏基准测试,我们将带有4个或8个工作线程的KVell与p2KVS-4和p2KVS-8进行比较,如图20所示。我们将KVell的页面缓存大小配置为4GB,这消耗了可接受程度的内存,比每个RocksDB实例的8MB块缓存大得多。即使使用这种配置,由于内存中索引较大,KVell的最大内存消耗是22 GB,而p2KVS的内存消耗是3 GB。
- 在写密集型工作负载(LOAD、A和F)下,p2KVS 的性能高于KVell。p2KVS 的点查询性能与KVell(工作负载B和D)相似,SCAN性能高于KVell(工作负载E),在工作负载 C 下,KVell由于具有大页面缓存和全内存索引,吞吐量高于p2KVS。
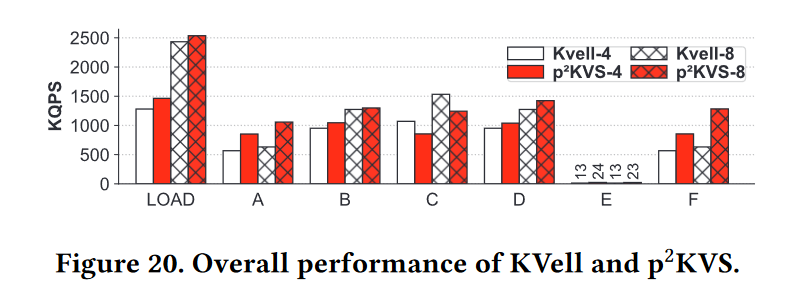
-
我们还记录并比较p2kv -8和KVell-8在连续100M随机写工作负载下的IO带宽、内存和CPU的利用率。KVell-8和p2KVS-8的吞吐量分别为2.5 MQPS和3.0 MQPS。
- 如图21a所示,KVell虽然使用了就地更新来减少写放大,但在小型的128字节KV写操作下,只消耗约300 MB/s IO带宽。相比之下,LSM-tree更适合聚合小型IOs,使p2KVS能够充分利用IO带宽。
- 图21b显示,即使减去页面缓存的占用空间,KVell仍然比p2KVS多使用2x内存,因为它将所有索引存储在内存中,而LSM-tree则对磁盘上的数据进行排序以减少索引大小。同时,KVell的每个线程都维护一个较大的索引,导致每个核的平均CPU利用率超过80%。但是,p2KVS下的每个RocksDB实例在前台和后台运行多个线程,分别执行日志记录和压缩。因此,虽然p2KVS的总CPU利用率更高,但每个核消耗大约50%的CPU,如图21c和21d所示。这意味着p2KVS更适合于多核硬件环境,不依赖于单核性能。因此,尽管KVell使用了一个较大的内存索引和页面缓存来获得比RocksDB更高的性能,但p2KVS可以通过使用更少的硬件资源来利用快速ssd来获得比KVell更好的性能。
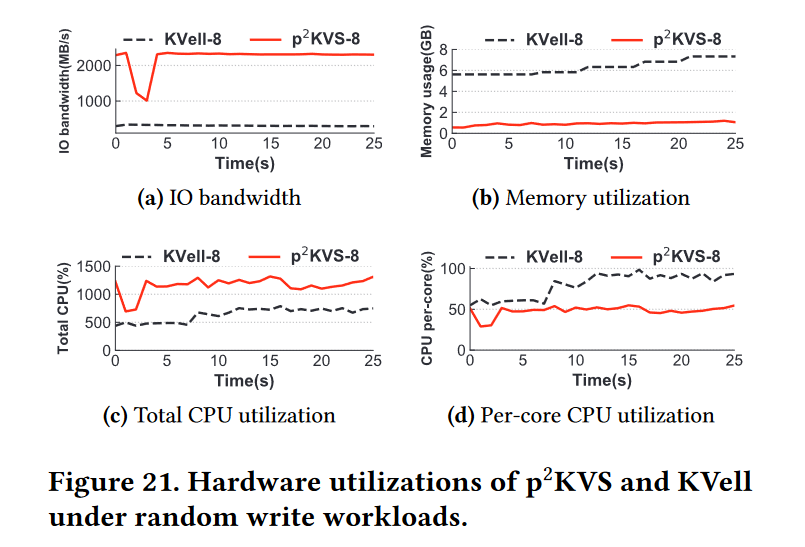
Portability
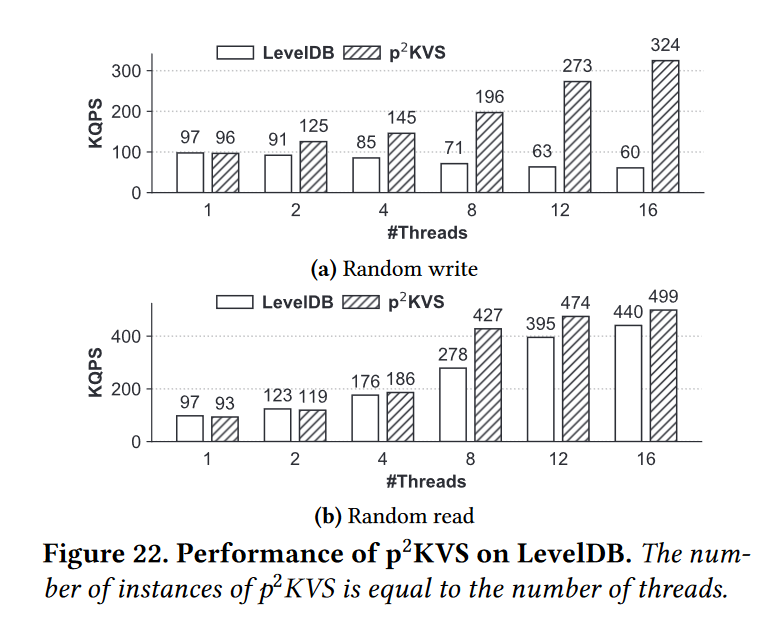
- 如4.6节所述,除了RocksDB,我们还将p2KVS移植到另外两个KVS, LevelDB和WiredTiger。在本节中,我们将评估p2KVS对提高两个KVS的并行性的效果。
- 图22显示了微基准测试下基于LevelDB实例的p2KVS的吞吐量。结果表明,即使LevelDB没有像RocksDB那样提供实例内并行性优化(例如,流水线写和多get), p2KVS仍然可以比单线程LevelDB分别提高 3.4x 和 5.3x 的随机写和读性能。通过多线程,p2KVS 为 LevelDB 带来了写并行性,而不会损失读性能。
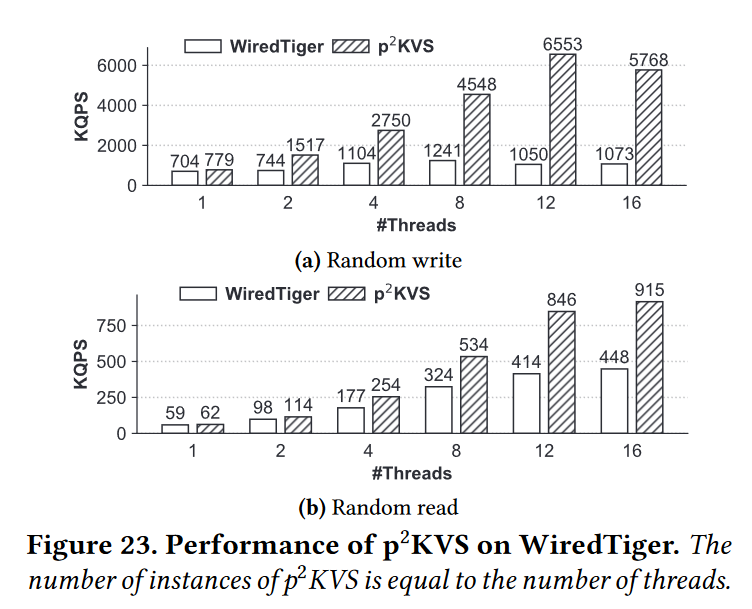
- p2KVS WiredTiger。图23显示了p2KVS在WiredTiger上的吞吐量。虽然WiredTiger不支持批写,但p2KVS仍然可以有效地将其读写吞吐量分别提高到8.4和15。在相同的线程数下,p2KVS的性能优于WiredTiger。此外,当worker的数量超过12时,写性能会下降,这意味着并行性的好处不足以弥补过多实例的开销。
Related Works
优化 WAL 和 Mt
- 一些研究尝试直接解决写 WAL 或 MT 步骤中的低性能问题。
- WAL
- SIGMOD’18 FASTER 提出了混和日志机制来在 DRAM 上存储日志的大部分,从而提升 WAL 的性能,但是牺牲了快速持久化
- VLDB’10 Aether 采用了一些复杂的方法,如早期锁释放和 Flush 管道,以减少并发引起的小日志写入争用。
- VLDB’20 Taurus: 通过使用日志序列号跟踪和编码事务,进一步优化这些技术并实现高效的并行日志记录方案。
- FAST’21 SpanDB:通过使用异步请求接口,SPDK通过基于轮询的IO提供异步组日志记录和请求处理。
- Memory
- FloDB, Accordion, WipDB, CruiseDB 通过修改内存组件的数据结构来提高 MemTable 的写性能。
- FloDB 和 Accordion 在基于skiplist的MemTable顶部添加缓冲区。
- WipDB 将 skiplist 替换为多个大型哈希表,并将 kv 对压缩到内存中而不是SSD中
- CruiseDB 根据工作负载和 SLA 动态调整 MemTable 的大小,减少写阻塞。
- p2KVS 兼容这些工作,并可以吸收他们的思想,同时使用高效的并行调度来避免WAL和内存结构上的争用
优化 LSM 压缩
- 为了有效利用 SSD 的带宽,许多解决方案通过修改 LSM-tree 结构来降低写放大。
- PebblesDB[46]设计了一个碎片化的 lsm-树结构,它允许在树级别上重叠键范围,并减少了大部分压缩开销。
- LSM-trie[50]、SifrDB[43]、Dostoevsky[18]、SlimDB[47] 和 ChameleonDB[58] 也设计了一些 LSM-tree 的变体,通过允许重叠键范围来减轻写放大
- ForestDB[1]、WiscKey[41]、lwb-tree[53]、HashKV[9]、UniKV[57]、DiffKV[38]采用KV分离机制,将KV对存储在多个日志文件中,并以LSM-tree级别记录键指针对,减少了大容量KV对的写放大。
- 虽然p2KVS的共同目标是优化基于lsm树的kvs的IO效率,但作为一个用户空间调优器,它与这些解决方案是正交和互补的,并且具有高度的可移植性,可以在现有的kvs上实现。
设计非 LSM
- 一些研究设计了新的高性能ssd结构来代替lsm树。
- KVell[36]在内存中维护大型基于b树的索引和页面缓存,以确保现代快速ssd上的GET和SCAN性能。
- uDepot[33]将数据存储在由哈希表映射的无序段中,并通过利用任务运行时系统的异步用户空间IO来充分利用ssd盘。
- Tucana[45]使用B𝜖-tree来减少开销和压缩的IO放大。
- SplinterDB[14]基于B𝜖-tree设计STB𝜖-tree,针对硬件并行度高的ssd进行优化。
- 虽然这些新的索引结构充分利用了现代SSD,但p2KVS采用了一种正交方法,将KVS和SSD视为黑盒,因此继承了广泛使用和优化良好的基于lsm树的KVS(如RocksDB)和SSD经过时间考验的理想特性,提供了高可移植性。
分片 KVS
- 分布式数据库将表空间分区到多个平面上,并将它们存储在节点之间的不同KVS实例中。[2,11,27,60]
- HBase, Bigtable,Nova-LSM,SolarDB
- 最近,运行在高性能硬件上的基于LSM-tree的OLTP存储引擎使用了多个LSM-tree实例,每个实例用于存储一个表、子表或索引[19,26,52]。
- The RocksDB Experience, X-Engine,Revisiting the Design of LSM-tree Based OLTP Storage Engine with Persistent Memory
- 使用特定的接口语义(例如列)或动态调度策略来确定键值对所在的实例。
- 而p2KVS采用键空间分片的方式,在不使用数据库语义的情况下,均匀地将 KVs 分配给多个 worker,加快了全局 KVs 的速度。
Conclusion
- 在生产级键-值存储环境中,系统管理员希望通过简单地将慢速hdd替换为快的ssd来获得一致的性能提升。结果往往令人失望,特别是对于普遍存在的小型KV工作负载。我们发现,在单线程和并发的写工作负载下,KVS写进程中的前台操作(日志记录和索引)可能成为严重的性能瓶颈。我们提出了一种便携式并行引擎p2KVS,基于lsm树的KVS的多个实例,以有效和高效地执行KV操作。p2KVS旨在利用这些实例之间和实例内部固有的并行性,以充分利用现代CPU、内存和存储硬件提供的处理能力。与最先进的RocksDB相比,p2KVS的写性能和读性能分别提高了4.6x和5.4x
一些问题
Multiget 带来的性能提升和数据路由策略之间的关系
- hash 公平路由之后一定程度丢失了数据的局部性信息,为什么 multiget 性能还能带来这么多优势
MultiGet Performance · facebook/rocksdb Wiki
Multiget
- 在底层的RocksDB实现中查找键非常复杂。这种复杂性导致了大量的计算开销,主要是由于探测布隆过滤器时缓存丢失、虚函数调用分发、键比较和IO。需要查找许多键来处理应用程序级请求最终会在一个循环中调用 Get() 来读取所需的kv。通过提供接收一批键的 MultiGet() API, RocksDB 可以通过减少虚函数调用和 pipeline cache miss 的数量来提高 CPU 查找的效率。此外,可以通过并行执行 IO 来减少延迟。
读路径
- 一个典型的 RocksDB 数据库实例有多个级别,每个级别包含几十到数百个SST文件。点查找经过以下几个阶段(为了简单起见,我们忽略合并操作数并假设所有操作都是Put)
- 可变memtable被查找。如果为memtable配置了bloom过滤器,则使用整个键或前缀探测该过滤器。如果结果为正,则执行memtable rep查找。
- 如果没有找到键,将使用与#1相同的进程查找 0 个或多个不可变memtables
- 接下来,逐级查找SST文件如下-
- 在L0中,每个SST文件都是按倒序查询的 (因为倒序顺序即为新到旧)
- 对于L1及以上,每一层都有一个SST文件元数据对象的 vector,每个元数据对象包括文件中的最高键和最低键。在这个向量中执行二进制搜索,以确定与所需键重叠的文件。有一个辅助索引,它使用关于 LSM 中文件范围的预计算信息来确定下一层中与给定文件重叠的文件集。在 L1 中执行完整的二分搜索,该索引用于缩小后续级别的二分搜索边界。这就是所谓的分数级联。fractional cascading
- 一旦找到候选文件,就加载该文件的 bloom filter 块(从块缓存或磁盘),并探测 key。这个探测很可能会导致 CPU cache miss。在很多情况下,最底层不会有 bloom filter。
- 如果探测结果为阳性,则加载SST文件索引块并进行二进制查找,找到目标数据块。筛选器和索引块可能必须从磁盘读取,但通常它们要么固定在内存中,要么被频繁地访问,以便在块缓存中找到它们。
- 加载数据块并进行二进制搜索以找到密钥。数据块查找更有可能在块缓存中丢失,从而导致IO。需要注意的是,每个块缓存查找也可能导致CPU缓存丢失,因为块缓存是由哈希表索引的。
- 对每一层重复步骤 #3,L2和更高一级的惟一区别是SST文件查找的部分级联。
MultiGet 性能优化
- 让我们考虑具有良好参考局部性的工作量的情况。在这种工作负载中连续的点查找可能会重复访问相同的 SST 文件和索引/数据块。对于这样的工作负载,MultiGet提供了以下优化-
- 当选择。设置 cache_index_and_filter_blocks=true 时,SST文件的过滤块和索引块将在每次键查找时从块缓存中提取。在有多个线程执行读操作的系统上,这将导致 LRU 互斥锁上的严重锁争用。对于与 SST 文件密钥范围重叠的整批密钥,MultiGet 只在块缓存中查找过滤器和索引块一次,从而大大减少了LRU互斥锁争用。
- 在步骤1、2和3c中,由于bloom filter探针,CPU cache miss会发生。假设一个数据库有6个级别,大多数键都在最底层找到,平均有2个L0文件,我们将有~6次缓存丢失,因为在SST文件中查找过滤器。如果配置了memtable bloom过滤器,可能会有额外的1-2个缓存丢失。通过对每个阶段的查找进行批处理,过滤器缓存行访问可以流水线化,从而隐藏了缓存 miss 延迟。
- 在大型数据库中,读取数据块很可能需要IO。这引入了延迟。MultiGet能够并行地对同一个SST文件中的多个数据块发出IO请求,从而减少延迟。这依赖于底层Env实现在同一线程中对并行读取的支持。在Linux上,PosixEnv 具有使用IO Uring接口为MultiGet()做并行IO的能力。IO Uring 是从5.1开始在Linux内核中引入的一种新的异步IO实现。注意,MultiGet有多种实现。只有返回void的方法执行并行IO。
